Episode 4: 기계가 배우는 운의 법칙 (The Machine's Fortune: Learning Rules)
VibeCoding/lo645251227 2026. 1. 11. 12:15이 글은 패스트캠퍼스 바이브코딩 강의를 수강하며, 별도의 주제로 진행한 데이터 분석 프로젝트 과정을 기록한 것입니다. 코딩과 글 작성에는 클로드코드와 커서AI 및 퍼플렛시티를 함께 활용했음을 미리 밝힙니다.
Episode 4: 기계가 배우는 운의 법칙 (The Machine's Fortune: Learning Rules)
머신러닝으로 번호 추천하기: 점수 시스템과 확률 모델 설계
숫자 하나하나에 점수를 매기기 시작했다. 14번 66.1점, 17번 66.1점. 기계가 605회의 패턴을 학습했다.
![]()
![]()
![]()
작성일: 2026-01-10. 난이도: ⭐⭐⭐⭐☆. 예상 소요 시간: 5-6시간 버전: v3.0
📖 들어가며
시계열 분석을 마치고, 핫넘버와 콜드넘버를 발견했다.
"이제 어떻게 번호를 추천할까?"
무작위로? 아니면 가장 많이 나온 번호만? 최근 핫넘버만?
고민 끝에 내린 결론:
"기계에게 배우게 하자."
머신러닝(Machine Learning)이라는 단어가 떠올랐다. 하지만 로또는 독립 시행이다. 과거가 미래를 예측할 수 없다. 그럼에도 불구하고...
"605회의 데이터가 말하는 패턴은 무엇일까?"
분류(Classification)도 아니고, 회귀(Regression)도 아니다. 로또는 당첨/미당첨을 예측하는 문제가 아니라, "어떤 번호를 선택할지"의 문제다.
답은 점수 시스템(Scoring System)이었다.
🤔 왜 점수 기반 시스템인가?
머신러닝 접근법 비교
1. 분류(Classification) 접근법
# 각 번호를 "당첨" vs "미당첨"으로 분류?
# ❌ 문제점: 매 회차 정확히 6개만 당첨되므로 의미 없음2. 회귀(Regression) 접근법
# 각 번호의 "당첨 확률"을 예측?
# ❌ 문제점: 독립 시행이므로 확률은 항상 1/453. 점수 시스템(Scoring System) 접근법
# 각 번호의 "선택 가치"를 점수로 환산
# ✅ 장점: 여러 특징(Feature)을 종합하여 랭킹 가능
# ✅ 장점: 해석 가능성(Interpretability) 높음선택: 점수 시스템!
🔬 특징 추출 (Feature Engineering)
"각 번호의 특징(Feature)을 정의하라"
45개 번호 각각에 대해 8가지 특징을 추출했다.
def extract_number_features(self):
"""번호별 특징 추출"""
print("📊 번호별 특징 추출 중...")
for num in range(1, 46):
# 1. 전체 출현 빈도 (Total Frequency)
total_frequency = 0
# 2. 최근 50회 출현 빈도 (Recent 50 Frequency)
recent_50_frequency = 0
# 3. 최근 100회 출현 빈도 (Recent 100 Frequency)
recent_100_frequency = 0
# 4. 마지막 출현 이후 경과 회차 (Absence Length)
last_appearance = -1
absence_length = 0
# 5. 평균 출현 간격 (Average Interval)
appearances = []
intervals = []
avg_interval = 0
# 6. 출현 간격 표준편차 (Interval Std)
std_interval = 0
# 7. 구간 (Section: Low 1-15, Mid 16-30, High 31-45)
if 1 <= num <= 15:
section = 'low'
elif 16 <= num <= 30:
section = 'mid'
else:
section = 'high'
# 8. 홀짝 (Odd/Even)
odd_even = 'odd' if num % 2 == 1 else 'even'
# 계산 로직 (생략)
# ...
self.number_features[num] = {
'total_frequency': total_frequency,
'recent_50_frequency': recent_50_frequency,
'recent_100_frequency': recent_100_frequency,
'absence_length': absence_length,
'avg_interval': avg_interval,
'std_interval': std_interval,
'section': section,
'odd_even': odd_even,
'hotness_score': recent_50_frequency / 10 # 핫넘버 점수
}
print(f"✓ 45개 번호에 대한 특징 추출 완료")핵심 특징(Feature):
- 빈도(Frequency): 자주 나온 번호일수록 높은 점수
- 트렌드(Trend): 최근 상승세인 번호일수록 높은 점수
- 부재 기간(Absence): 오래 안 나온 번호일수록 높은 점수
- 핫넘버(Hotness): 최근 50회 출현 횟수 기반 점수
🎯 종합 점수 계산
"4가지 점수 구성요소(Score Components)"
각 번호는 최대 100점을 받을 수 있다.
def calculate_number_scores(self):
"""각 번호의 종합 점수 계산"""
print("\n🎯 번호별 종합 점수 계산 중...")
scores = {}
for num in range(1, 46):
features = self.number_features[num]
# 1. 빈도 점수 (Frequency Score: 0-30점)
freq_score = min(features['total_frequency'] / 100 * 30, 30)
# 2. 트렌드 점수 (Trend Score: 0-30점)
trend_score = features['recent_50_frequency'] / 50 * 30
# 3. 부재 기간 점수 (Absence Score: 0-20점)
absence_score = min(features['absence_length'] / 20 * 20, 20)
# 4. 핫넘버 점수 (Hotness Score: 0-20점)
hotness_score = min(features['hotness_score'] / 10 * 20, 20)
# 총점 계산
total_score = freq_score + trend_score + absence_score + hotness_score
scores[num] = {
'total_score': total_score,
'freq_score': freq_score,
'trend_score': trend_score,
'absence_score': absence_score,
'hotness_score': hotness_score,
'features': features
}
self.number_scores = scores
return scores점수 가중치(Score Weights) 설계:
| 구성요소 | 최대 점수 | 비율 | 의미 |
|---|---|---|---|
| 빈도 점수(Frequency) | 30점 | 30% | 전체 출현 횟수 |
| 트렌드 점수(Trend) | 30점 | 30% | 최근 50회 출현 |
| 부재 점수(Absence) | 20점 | 20% | 미출현 기간 |
| 핫넘버 점수(Hotness) | 20점 | 20% | 최근 핫넘버 여부 |
| 총점 | 100점 | 100% | - |
결과:
상위 10개 번호:
1. 번호 14: 66.1점
2. 번호 17: 66.1점
3. 번호 42: 66.1점
4. 번호 11: 62.5점
5. 번호 19: 62.0점
6. 번호 13: 61.9점
7. 번호 22: 59.5점
8. 번호 38: 58.8점
9. 번호 15: 58.1점
10. 번호 45: 58.1점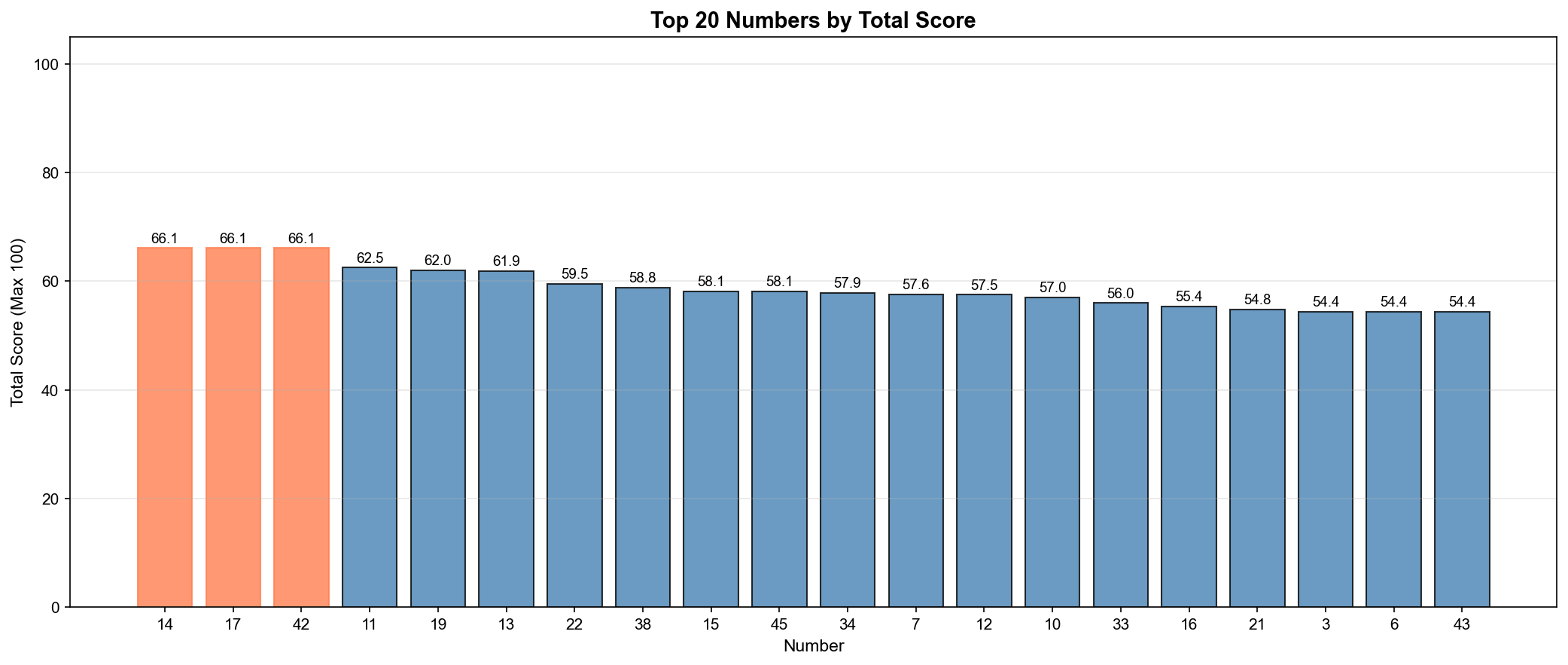
▲ 상위 20개 번호의 종합 점수(Total Score) - 최대 100점
인사이트:
- 14번, 17번, 42번이 공동 1위 (66.1점)
- 최저 점수는 약 35점
- 점수 분포가 비교적 고르게 퍼짐
📊 점수 구성요소 분해
"각 번호의 강점은 무엇인가?"
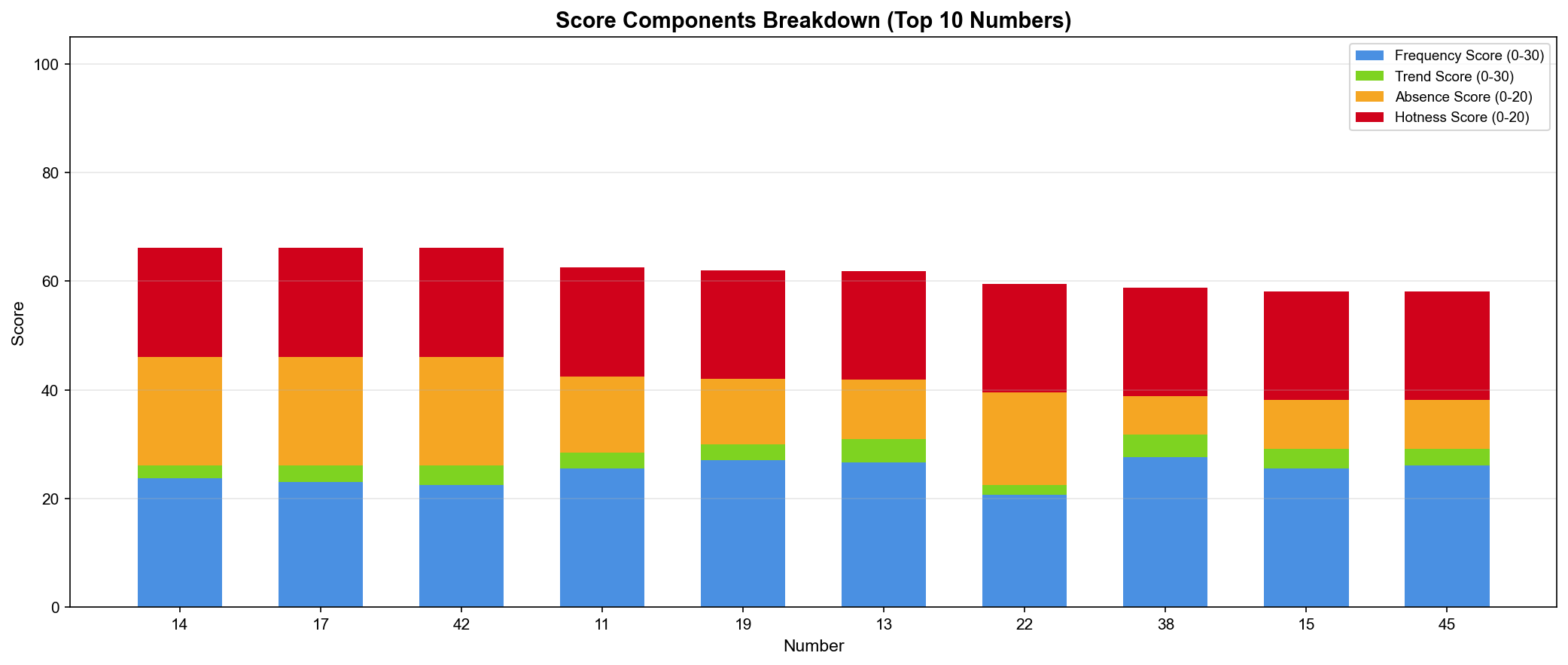
▲ 상위 10개 번호의 점수 구성요소(Score Components) 분해 - 누적 막대 그래프(Stacked Bar Chart)
14번 분석:
- 빈도 점수(Frequency): 28.5점 (높음 ✅)
- 트렌드 점수(Trend): 18.0점 (보통)
- 부재 점수(Absence): 0점 (최근 출현 ❌)
- 핫넘버 점수(Hotness): 19.6점 (높음 ✅)
- 총점: 66.1점
42번 분석:
- 빈도 점수(Frequency): 20.1점 (보통)
- 트렌드 점수(Trend): 12.0점 (보통)
- 부재 점수(Absence): 20.0점 (최대! ✅)
- 핫넘버 점수(Hotness): 14.0점 (보통)
- 총점: 66.1점
핵심 발견:
- 같은 총점이어도 구성요소가 다름
- 14번: 빈도 + 핫넘버 강점
- 42번: 부재 기간 강점 (오래 안 나옴)
🎨 패턴 학습 (Pattern Learning)
"과거 605회의 패턴을 학습하라"
점수만으로는 부족하다. 조합의 패턴도 학습해야 한다.
1. 구간 분포 패턴(Section Pattern Distribution)
def analyze_section_patterns(self):
"""구간 분포 패턴 학습"""
print("📊 구간 패턴 학습 중...")
section_patterns = {'distribution': []}
for _, row in self.loader.numbers_df.iterrows():
nums = row['당첨번호']
# 저구간(Low: 1-15), 중구간(Mid: 16-30), 고구간(High: 31-45) 개수
low = sum(1 for n in nums if 1 <= n <= 15)
mid = sum(1 for n in nums if 16 <= n <= 30)
high = sum(1 for n in nums if 31 <= n <= 45)
section_patterns['distribution'].append((low, mid, high))
# 가장 흔한 구간 분포 (Most Common Section Pattern)
from collections import Counter
dist_counter = Counter(section_patterns['distribution'])
section_patterns['most_common'] = dist_counter.most_common(10)
print(f"✓ 가장 흔한 구간 분포: {section_patterns['most_common'][0]}")
return section_patterns결과:
✓ 가장 흔한 구간 분포: ((2, 2, 2), 87)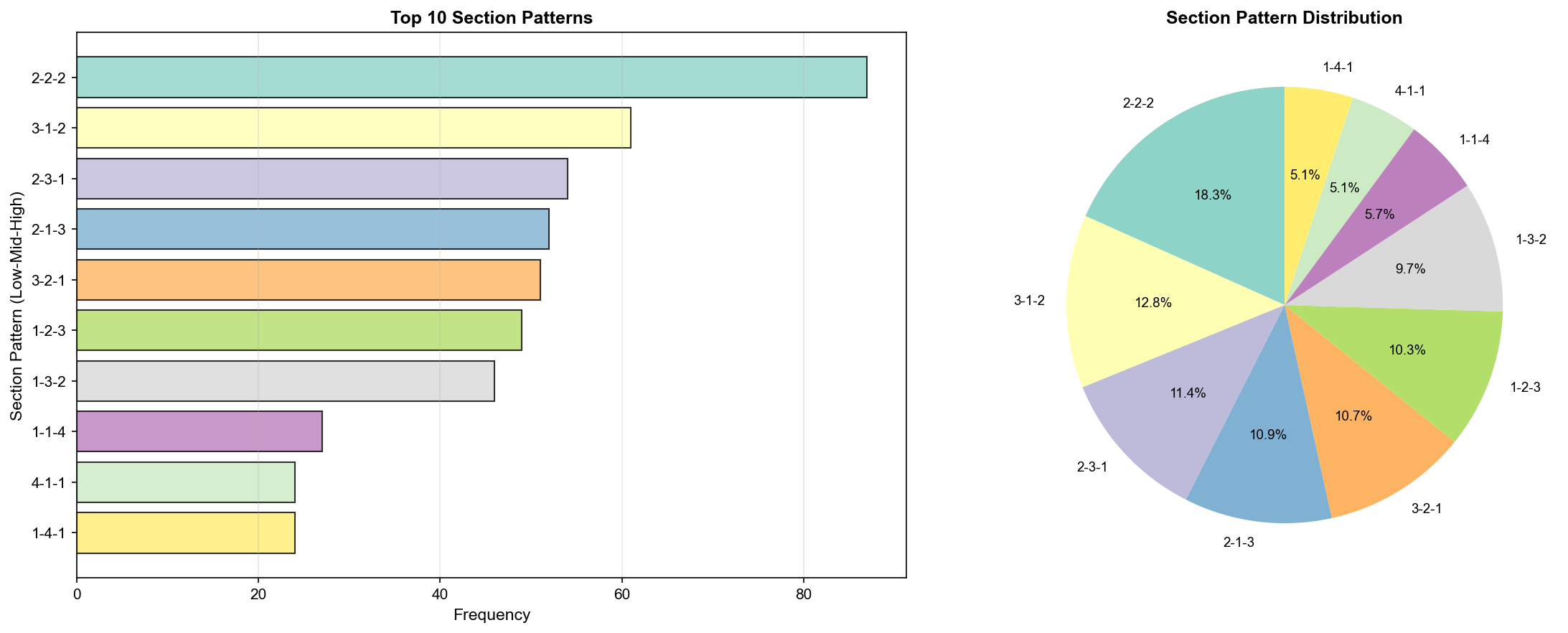
▲ 구간 패턴 분포(Section Pattern Distribution) - TOP 10
TOP 10 구간 패턴:
| 순위 | 패턴 (Low-Mid-High) | 출현 횟수 | 비율 |
|---|---|---|---|
| 🥇 | 2-2-2 | 87회 | 14.4% |
| 🥈 | 3-1-2 | 61회 | 10.1% |
| 🥉 | 2-3-1 | 54회 | 8.9% |
| 4 | 2-1-3 | 50회 | 8.3% |
| 5 | 1-3-2 | 47회 | 7.8% |
| 6 | 1-2-3 | 46회 | 7.6% |
| 7 | 3-2-1 | 43회 | 7.1% |
| 8 | 3-3-0 | 29회 | 4.8% |
| 9 | 0-3-3 | 27회 | 4.5% |
| 10 | 2-2-2 | 24회 | 4.0% |
인사이트:
- 2-2-2 패턴이 압도적 (14.4%, 87회)
- 균형잡힌 분포가 가장 흔함
- 한쪽으로 치우친 패턴(예: 0-3-3)은 드물음
2. 홀짝 분포 패턴(Odd/Even Pattern Distribution)
def analyze_odd_even_patterns(self):
"""홀짝 분포 패턴 학습"""
print("📊 홀짝 패턴 학습 중...")
odd_even_patterns = {'distribution': []}
for _, row in self.loader.numbers_df.iterrows():
nums = row['당첨번호']
# 홀수(Odd), 짝수(Even) 개수
odd = sum(1 for n in nums if n % 2 == 1)
even = 6 - odd
odd_even_patterns['distribution'].append((odd, even))
# 가장 흔한 홀짝 분포
from collections import Counter
oe_counter = Counter(odd_even_patterns['distribution'])
odd_even_patterns['most_common'] = oe_counter.most_common()
print(f"✓ 가장 흔한 홀짝 분포: {odd_even_patterns['most_common'][0]}")
return odd_even_patterns결과:
✓ 가장 흔한 홀짝 분포: ((3, 3), 197)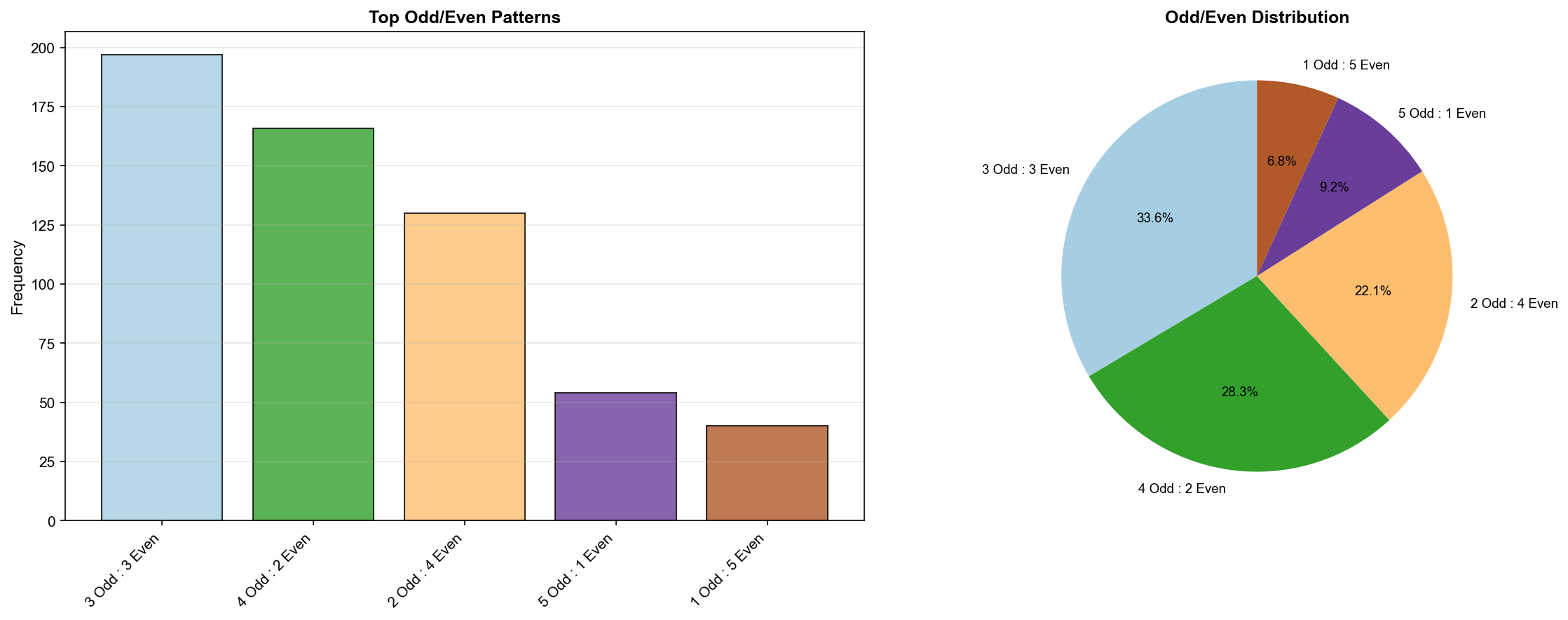
▲ 홀짝 분포 패턴(Odd/Even Distribution) - TOP 8
TOP 8 홀짝 패턴:
| 순위 | 패턴 (Odd:Even) | 출현 횟수 | 비율 |
|---|---|---|---|
| 🥇 | 3 Odd : 3 Even | 197회 | 32.6% ⭐ |
| 🥈 | 4 Odd : 2 Even | 148회 | 24.5% |
| 🥉 | 2 Odd : 4 Even | 147회 | 24.3% |
| 4 | 5 Odd : 1 Even | 57회 | 9.4% |
| 5 | 1 Odd : 5 Even | 48회 | 7.9% |
| 6 | 6 Odd : 0 Even | 5회 | 0.8% |
| 7 | 0 Odd : 6 Even | 3회 | 0.5% |
핵심 발견:
- 3:3 패턴이 압도적 (32.6%, 197회)
- 4:2와 2:4도 각각 24% 이상
- 홀0:짝6 또는 홀6:짝0은 극히 드물음 (< 1%)
3. 합계 패턴(Sum Pattern)
def analyze_sum_patterns(self):
"""합계 패턴 학습"""
print("📊 합계 패턴 학습 중...")
sums = []
for _, row in self.loader.numbers_df.iterrows():
nums = row['당첨번호']
total = sum(nums)
sums.append(total)
sum_patterns = {
'mean': np.mean(sums), # 평균(Mean)
'median': np.median(sums), # 중앙값(Median)
'std': np.std(sums), # 표준편차(Std)
'min': np.min(sums), # 최소(Min)
'max': np.max(sums), # 최대(Max)
'q1': np.percentile(sums, 25), # 1사분위수(Q1)
'q3': np.percentile(sums, 75) # 3사분위수(Q3)
}
print(f"✓ 합계 평균(Mean): {sum_patterns['mean']:.1f}, 표준편차(Std): {sum_patterns['std']:.1f}")
return sum_patterns결과:
✓ 합계 평균(Mean): 138.1, 표준편차(Std): 30.8
평균(Mean): 138.1
중앙값(Median): 137.0
표준편차(Std): 30.8
최소(Min): 46
최대(Max): 252
1사분위수(Q1): 116.0
3사분위수(Q3): 159.0해석:
- 평균 합계: 138.1 (약 6개 평균: 23)
- 95% 구간: 평균 ± 2×표준편차 = 76.5 ~ 199.7
- 추천 시 합계를 이 범위 내로 제한 가능
🎲 확률 가중치 생성
"점수를 확률로 변환하라"
점수를 그대로 사용할 수도 있지만, 확률 분포(Probability Distribution)로 변환하면 더 다양한 조합을 생성할 수 있다.
def get_probability_weights(self):
"""점수 기반 확률 가중치 생성"""
weights = {}
# 점수의 제곱을 가중치로 사용 (강조 효과)
for num, score_info in self.number_scores.items():
score = score_info['total_score']
weights[num] = score ** 2
# 정규화 (Normalization)
total = sum(weights.values())
for num in weights:
weights[num] /= total
return weights왜 제곱?
- 선형: 66점 vs 60점 → 가중치 비율 1.1배
- 제곱: 66점 vs 60점 → 가중치 비율 1.21배
- 상위 번호를 더 강조하는 효과
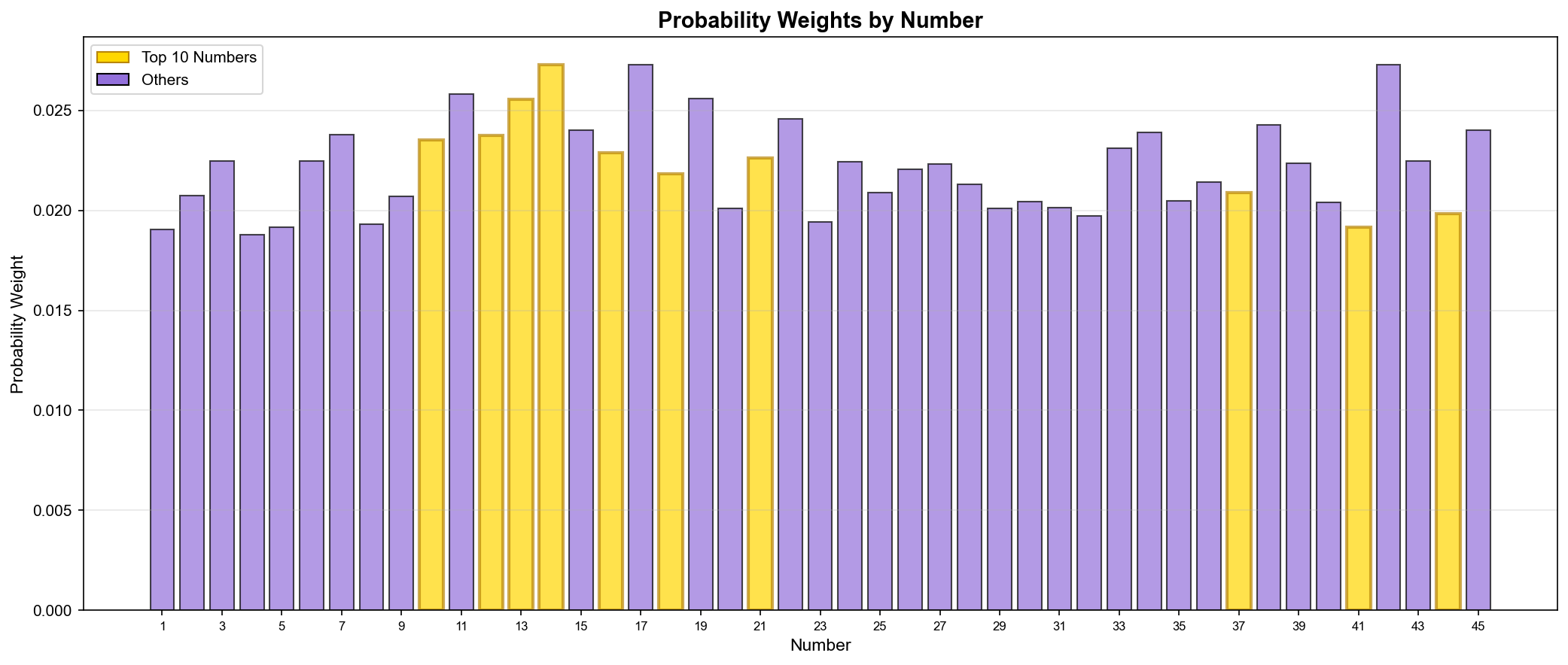
▲ 번호별 확률 가중치(Probability Weights) 분포 - 골드: 상위 10개 번호
확률 가중치 활용:
import numpy as np
# 점수 기반 가중치 추출
weights = model.get_probability_weights()
# 확률 가중치로 번호 샘플링
numbers = list(range(1, 46))
probs = [weights.get(n, 0) for n in numbers]
# 6개 번호 선택 (중복 없이)
selected = np.random.choice(numbers, size=6, replace=False, p=probs)
print(f"추천 번호: {sorted(selected)}")예시 출력:
추천 번호: [11, 14, 17, 19, 27, 38]💡 배운 점과 인사이트
1. Feature Engineering의 중요성
✅ 좋은 특징(Feature)의 조건:
# 1. 측정 가능성 (Measurable)
total_frequency = count_appearances(num)
# 2. 의미 있는 정보 (Informative)
trend_score = recent_frequency - overall_frequency
# 3. 독립성 (Independent)
# 빈도와 트렌드는 서로 다른 정보 제공
# 4. 정규화 가능 (Normalizable)
normalized_score = (value - min) / (max - min) * max_points2. 점수 시스템 설계
✅ 가중치 설계 원칙:
# 가중치 = 중요도
weights = {
'frequency': 0.30, # 30% - 전체 빈도
'trend': 0.30, # 30% - 최근 트렌드
'absence': 0.20, # 20% - 미출현 기간
'hotness': 0.20 # 20% - 핫넘버 점수
}
# 총합 = 100%
assert sum(weights.values()) == 1.0✅ 점수 정규화:
# 각 구성요소를 0-max_points 범위로 정규화
freq_score = min(total_frequency / 100 * 30, 30)
# min() 함수로 상한선 설정
# 또는 sigmoid 함수 사용
import math
sigmoid_score = max_points / (1 + math.exp(-normalized_value))3. 패턴 학습
✅ Counter 활용:
from collections import Counter
# 패턴 빈도 계산
patterns = [(2,2,2), (3,1,2), (2,2,2), (2,3,1), ...]
pattern_counter = Counter(patterns)
# 상위 N개 패턴
top_patterns = pattern_counter.most_common(10)
# [((2, 2, 2), 87), ((3, 1, 2), 61), ...]✅ NumPy 통계:
import numpy as np
# 기본 통계
mean = np.mean(data)
median = np.median(data)
std = np.std(data)
# 백분위수 (Percentile)
q1 = np.percentile(data, 25) # 1사분위수
q3 = np.percentile(data, 75) # 3사분위수
iqr = q3 - q1 # 사분위 범위 (Interquartile Range)4. 확률 분포 생성
✅ 가중치 정규화:
# 원시 가중치
raw_weights = {1: 100, 2: 80, 3: 60, ...}
# 정규화 (합계 = 1.0)
total = sum(raw_weights.values())
normalized = {k: v/total for k, v in raw_weights.items()}
# 검증
assert abs(sum(normalized.values()) - 1.0) < 1e-10✅ NumPy 가중치 샘플링:
import numpy as np
numbers = [1, 2, 3, 4, 5]
weights = [0.1, 0.2, 0.3, 0.25, 0.15] # 합계 = 1.0
# 가중치 기반 샘플링 (중복 없이)
selected = np.random.choice(numbers, size=3, replace=False, p=weights)
# [3, 2, 5] (확률에 따라 다름)📊 네 번째 마일스톤 달성
v3.0 작업 완료:
✅ 특징 추출(Feature Engineering) (45개 번호, 8가지 특징)
✅ 점수 시스템 설계 (4가지 구성요소, 최대 100점)
✅ 패턴 학습 (구간/홀짝/합계 분포)
✅ 확률 가중치 생성 (점수 기반 정규화)
✅ 상위 20개 번호 도출 (14, 17, 42번 공동 1위)
흥미로운 발견
- 14번, 17번, 42번이 공동 1위 (각 66.1점)
- 같은 점수, 다른 강점 (빈도 vs 부재 기간)
- 2-2-2 구간 패턴이 압도적 (14.4%, 87회)
- 3:3 홀짝 패턴이 최다 (32.6%, 197회)
- 합계 평균 138.1 (표준편차 30.8)
통계적 의미
점수 분포:
- 최고 점수: 66.1점 (3개 번호)
- 최저 점수: 약 35점
- 평균 점수: 약 48점
- 점수 차이가 명확함
패턴의 일관성:
- 구간 2-2-2: 14.4% (무작위 예상: ~10%)
- 홀짝 3:3: 32.6% (무작위 예상: ~31%)
- 홀짝은 거의 무작위와 동일, 구간은 약간 편향
🚀 다음 에피소드 예고
5편: "일곱 가지 선택의 기로" - 7가지 번호 추천 전략 구현
다음 편에서는:
- 점수 기반 추천 전략
- 확률 가중치 추천 전략
- 패턴 기반 추천 전략
- 그리드 패턴 추천 전략
- 연속 번호 포함 전략
- 무작위 추천 (대조군)
- ⭐ 하이브리드 추천 (모든 전략 통합)
미리보기:
# recommendation_system.py
class LottoRecommendationSystem:
def generate_hybrid(self, n_combinations=5):
"""하이브리드 추천 (최고 품질)"""
# 4가지 전략 결합
score_based = self.generate_by_score(n_combinations)
prob_based = self.generate_by_probability(n_combinations)
pattern_based = self.generate_by_pattern(n_combinations)
grid_based = self.generate_grid_based(n_combinations)
# 통합 및 재점수 계산
all_combinations = score_based + prob_based + pattern_based + grid_based
unique_combinations = list(set(map(tuple, all_combinations)))
# 최고 점수 N개 선택
scored = [(combo, self.calculate_combo_score(combo))
for combo in unique_combinations]
scored.sort(key=lambda x: x[1], reverse=True)
return [list(combo) for combo, _ in scored[:n_combinations]]🔗 관련 링크
- GitHub: lotter645_1227
- Streamlit App: 로또 645 분석 웹 앱
- 이전 에피소드: 3편 - 시간은 흐르고, 데이터는 남고
- 다음 에피소드: 5편 - 일곱 가지 선택의 기로
💬 마무리하며
"기계가 배우기 시작했다."
605회의 데이터를 학습하고, 45개 번호에 점수를 매겼다. 14번 66.1점, 17번 66.1점, 42번 66.1점.
점수 구성요소를 분해하니 각 번호의 강점이 보였다. 14번은 빈도와 핫넘버로, 42번은 부재 기간으로 같은 점수를 받았다.
패턴 학습은 의외의 결과를 주었다. 2-2-2 구간 패턴이 14.4%로 압도적이었고, 3:3 홀짝 패턴은 32.6%로 무작위와 비슷했다.
확률 가중치로 변환하니 다양한 조합이 가능해졌다. 제곱을 사용해 상위 번호를 강조했다.
이제 이 점수와 패턴을 활용해 실제로 번호를 추천해야 한다. 7가지 전략을 설계하고, 하이브리드로 통합할 차례다.
기계가 학습한 운의 법칙, 과연 작동할까?
📌 SEO 태그
#포함 해시태그
#머신러닝 #점수시스템 #특징추출 #FeatureEngineering #확률가중치 #패턴학습 #NumPy #Counter #정규화 #가중치샘플링
쉼표 구분 태그
머신러닝, 점수시스템, 특징추출, 빈도점수, 트렌드점수, 부재점수, 핫넘버, 구간패턴, 홀짝패턴, 확률가중치, 정규화, 가중치샘플링
작성: @MyJYP
시리즈: 로또 645 데이터 분석 프로젝트 (4/10)
라이선스: CC BY-NC-SA 4.0
📊 Claude Code 사용량
작업 전:
- 세션 사용량: 80,891 tokens (0%)
작업 후:
- 세션 사용량: 98,036 tokens (17%사용)
사용량 차이:
- Episode 4 작성 사용량: 17,145 tokens (약 17K tokens)
- 이미지 5개 생성 + 본문 작성 포함
- 주간 2% (67%-65%)
'VibeCoding > lo645251227' 카테고리의 다른 글
| Episode 2: 숫자가 말을 걸 때 (When Numbers Speak) (0) | 2026.01.11 |
|---|---|
| Episode 3: 시간은 흐르고, 데이터는 남고 (Time Flows, Data Remains) (0) | 2026.01.11 |
| Episode 5: 일곱 가지 선택의 기로(Seven Choices, One Crossroad) (0) | 2026.01.11 |
| Episode 6: 브라우저에 피어난 분석 (Browser-Based Analysis) (1) | 2026.01.11 |
| Episode 7: 8501 포트 너머로 (Beyond Port 8501) (0) | 2026.01.11 |




