이 글은 패스트캠퍼스 바이브코딩 강의를 수강하며, 별도의 주제로 진행한 데이터 분석 프로젝트 과정을 기록한 것입니다. 코딩과 글 작성에는 클로드코드와 커서AI 및 퍼플렛시티를 함께 활용했음을 미리 밝힙니다.
Episode 2: 숫자가 말을 걸 때 (When Numbers Speak)
연속 번호와 그리드 패턴의 비밀: 7x7 복권 용지로 보는 새로운 관점
6-7, 38-39... 연속 번호가 말을 걸기 시작했다. 그리고 복권 용지 위에서 숨겨진 패턴을 발견했다.
![]()
![]()
![]()
작성일: 2026-01-10 난이도: ⭐⭐⭐☆☆ 예상 소요 시간: 3-4시간. 버전: v2.0, v4.0
📖 들어가며
기본 통계 분석을 마치고 결과를 보던 중, 이상한 걸 발견했다.
"6-7이 15번이나 나왔다고?"
연속 번호가 유독 많이 나온다는 느낌. 단순한 우연일까, 아니면 패턴이 있는 걸까?
더 흥미로운 건 그다음이었다. 로또 복권을 사러 갔을 때, 그 작은 용지를 보다가 깨달았다.
"이거... 7x7 그리드잖아?"
1부터 45까지 번호가 7개씩 7줄로 배치되어 있었다. 숫자가 아니라 "위치"로 보면 어떨까? 복권 용지 왼쪽 위 모서리 번호들은 덜 나올까? 중앙 번호들은 더 많이 나올까?
숫자가 말을 걸기 시작했다.
🔢 연속 번호의 비밀
"56%의 회차에서 연속 번호가 나온다"
첫 번째 발견은 충격적이었다.
def find_consecutive_groups(numbers):
"""연속 번호 그룹 찾기"""
numbers = sorted(numbers)
groups = []
i = 0
while i < len(numbers) - 1:
if numbers[i+1] - numbers[i] == 1:
# 연속 시작
group = [numbers[i], numbers[i+1]]
j = i + 1
# 연속이 계속되는지 확인
while j < len(numbers) - 1 and numbers[j+1] - numbers[j] == 1:
group.append(numbers[j+1])
j += 1
groups.append(group)
i = j
else:
i += 1
return groups605회차 전체를 분석한 결과:
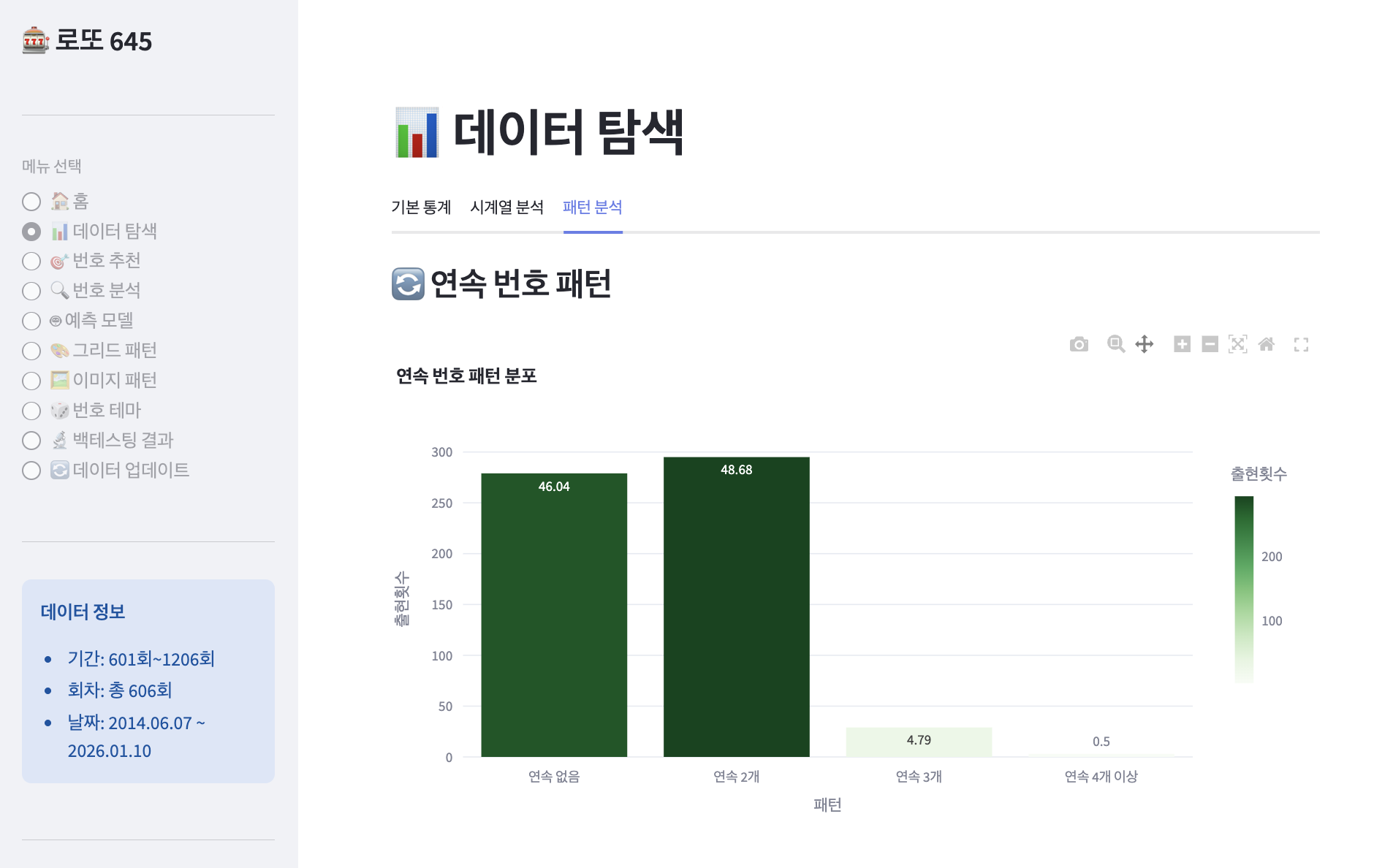
📊 연속 번호 출현 통계
==================================================
연속 없음: 278회 (46.10%)
연속 2개: 339회 (56.22%) ⭐
연속 3개: 30회 ( 4.98%)
연속 4개: 3회 ( 0.50%)
연속 5개 이상: 0회 ( 0.00%)핵심 발견:
- 절반 이상(53.9%)에서 연속 번호가 출현!
- 연속 2개가 가장 흔한 패턴
- 연속 5개 이상은 단 한 번도 없음
최다 출현 연속 조합 TOP 10
def analyze_consecutive_combinations(self):
"""가장 많이 나온 연속 조합 분석"""
consecutive_pairs = []
for _, row in self.loader.numbers_df.iterrows():
numbers = sorted(row['당첨번호'])
# 연속 쌍 찾기
for i in range(len(numbers) - 1):
if numbers[i+1] - numbers[i] == 1:
pair = (numbers[i], numbers[i+1])
consecutive_pairs.append(pair)
# 빈도 계산
from collections import Counter
counter = Counter(consecutive_pairs)
return counter.most_common(10)결과:
| 순위 | 연속 번호 | 출현 횟수 | 출현율 | 구간 |
|---|---|---|---|---|
| 🥇 | 6-7 | 15회 | 2.49% | 저구간(Low) |
| 🥈 | 38-39 | 14회 | 2.32% | 고구간(High) |
| 🥈 | 17-18 | 14회 | 2.32% | 중구간(Mid) |
| 4 | 3-4 | 12회 | 1.99% | 저구간(Low) |
| 4 | 14-15 | 12회 | 1.99% | 저구간(Low) |
| 6 | 37-38 | 10회 | 1.66% | 고구간(High) |
| 6 | 40-41 | 10회 | 1.66% | 고구간(High) |
| 6 | 18-19 | 10회 | 1.66% | 중구간(Mid) |
| 6 | 42-43 | 10회 | 1.66% | 고구간(High) |
| 10 | 1-2, 5-6, 27-28 | 9회 | 1.49% | - |
인사이트:
- 6-7이 압도적 1위 (15회, 2.49%)
- 세 구간 모두에서 골고루 출현
- 경계 부근 번호(14-15, 42-43)도 빈출
연속 4개의 전설
605회 중 단 3회만 기록된 연속 4개:
1️⃣ 655회 (2015.06.20): 37-38-39-40
2️⃣ 783회 (2017.12.02): 14-15-16-17
3️⃣ 1118회 (2024.05.04): 13-14-15-16통계적 의미:
- 확률: 0.50% (1/200)
- 약 200회에 1번 꼴
- 연속 5개 이상: 한 번도 없음
🎨 7x7 그리드의 발견
"숫자가 아니라 위치다"
어느 날 복권을 사러 갔을 때, 작은 용지를 보다가 깨달았다.
로또 복권 용지 구조 (7x7 그리드):
[ 1][ 2][ 3][ 4][ 5][ 6][ 7]
[ 8][ 9][10][11][12][13][14]
[15][16][17][18][19][20][21]
[22][23][24][25][26][27][28]
[29][30][31][32][33][34][35]
[36][37][38][39][40][41][42]
[43][44][45][ ][ ][ ][ ]아이디어:
- 숫자 "12"는 그냥 12가 아니라, Row 1, Col 4 위치
- 숫자 "1"은 모서리 위치
- 숫자 "25"는 정중앙 위치
만약 사람들이 복권 용지에서 중앙을 더 자주 선택한다면?
만약 모서리는 덜 선택한다면?
이건 단순한 숫자 분석이 아니라 공간 통계 문제다!
GridPatternAnalysis 클래스 설계
class GridPatternAnalysis:
"""복권 용지 그리드 패턴 분석 클래스"""
def __init__(self, loader):
self.loader = loader
self.rows = 7
self.cols = 7
# 번호 → 그리드 좌표 매핑
self.number_to_position = {}
number = 1
for row in range(self.rows):
for col in range(self.cols):
if number <= 45:
self.number_to_position[number] = (row, col)
number += 1
# 위치별 출현 빈도
self.position_heatmap = np.zeros((7, 7))
def get_position(self, number):
"""번호의 그리드 좌표 반환 (row, col)"""
row = (number - 1) // 7
col = (number - 1) % 7
return (row, col)
def get_zone(self, row, col):
"""그리드 위치의 구역 반환"""
# 모서리 (4칸): 1, 7, 43, 45
if (row, col) in [(0, 0), (0, 6), (6, 0), (6, 6)]:
return "corner"
# 가장자리 (20칸): 첫/마지막 행/열
elif row == 0 or row == 6 or col == 0 or col == 6:
return "edge"
# 중앙부 (9칸): 17, 18, 19, 24, 25, 26, 31, 32, 33
elif 2 <= row <= 4 and 2 <= col <= 4:
return "center"
# 중간 (12칸): 나머지
else:
return "middle"그리드 구역 분류:
C = Corner (모서리)
E = Edge (가장자리)
M = Middle (중간)
X = Center (중앙부)
C E E E E E C
E M M M M M E
E M X X X M E
E M X X X M E
E M X X X M E
E M M M M M E
C E E . . . .📊 위치별 출현 빈도 분석
히트맵 생성
def analyze_position_frequency(self):
"""위치별 출현 빈도 분석"""
# 모든 당첨번호의 위치 수집
for _, row in self.loader.numbers_df.iterrows():
winning_numbers = row['당첨번호']
for num in winning_numbers:
r, c = self.get_position(num)
self.position_heatmap[r, c] += 1
# 통계
valid_freqs = []
for number in range(1, 46):
r, c = self.get_position(number)
freq = self.position_heatmap[r, c]
valid_freqs.append((freq, r, c, number))
valid_freqs.sort(reverse=True)
max_freq, max_r, max_c, max_num = valid_freqs[0]
min_freq, min_r, min_c, min_num = valid_freqs[-1]
print(f"🔥 최다 출현: Row {max_r}, Col {max_c} (번호 {max_num}) - {int(max_freq)}회")
print(f"❄️ 최소 출현: Row {min_r}, Col {min_c} (번호 {min_num}) - {int(min_freq)}회")
print(f"📊 평균 출현: {np.mean(self.position_heatmap):.1f}회")결과:
🔥 최다 출현: Row 1, Col 4 (번호 12) - 97회
❄️ 최소 출현: Row 0, Col 4 (번호 5) - 64회
📊 평균 출현: 74.0회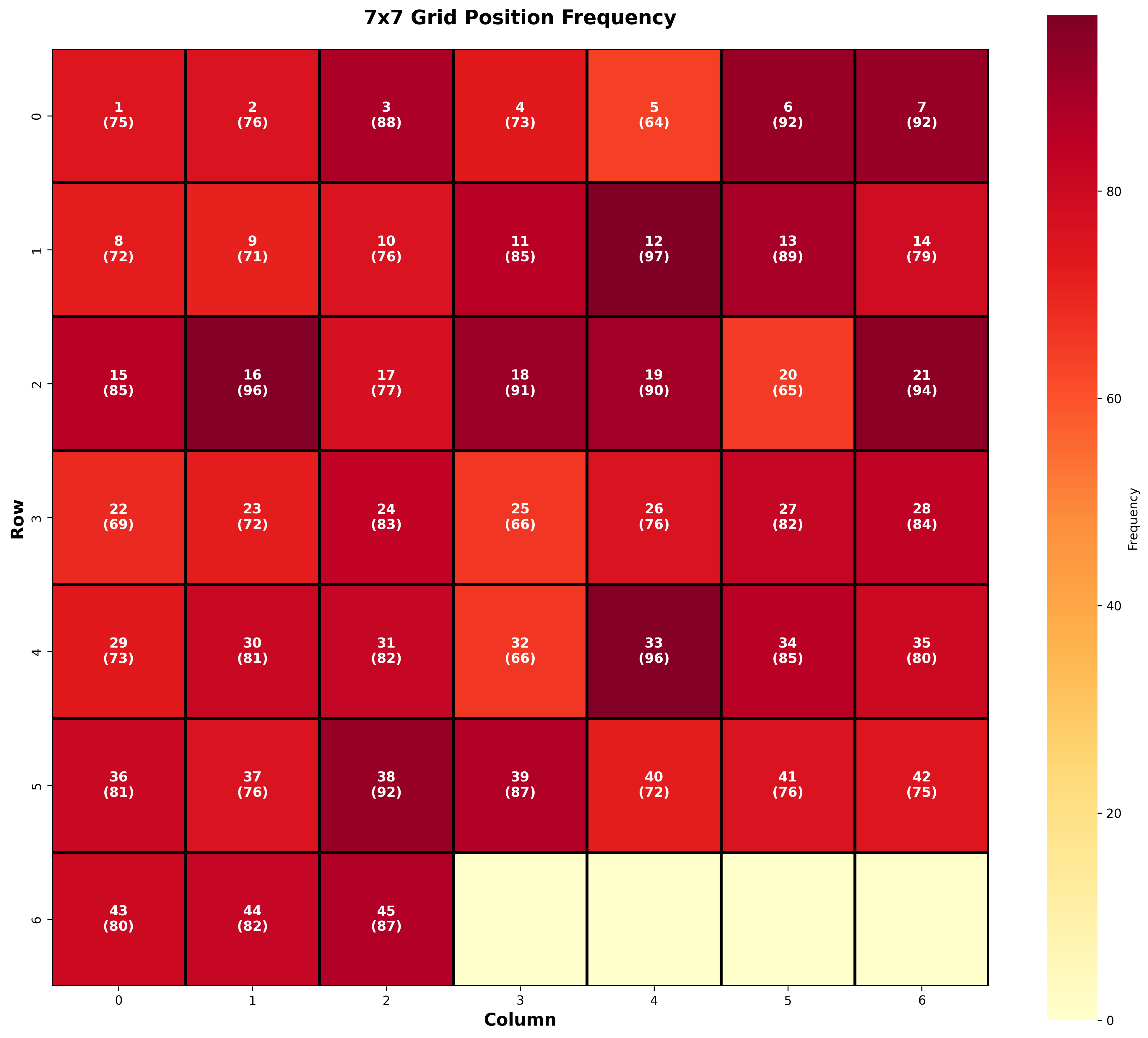
▲ 7x7 그리드 위치별 출현 빈도 히트맵(Heatmap) - 진한 색: 많이 출현
인사이트:
- 최대-최소 차이: 33회 (약 51% 차이!)
- 12번(Row 1, Col 4)이 압도적 1위
- 5번(Row 0, Col 4)이 최하위
🏘️ 구역별 분석
각 구역의 평균 출현 횟수
def analyze_zone_distribution(self):
"""구역별 분포 분석"""
zone_counts = defaultdict(int)
zone_cells = defaultdict(int)
for number in range(1, 46):
r, c = self.get_position(number)
zone = self.get_zone(r, c)
freq = self.position_heatmap[r, c]
zone_counts[zone] += freq
zone_cells[zone] += 1
# 구역별 평균
results = {}
for zone in ['corner', 'edge', 'middle', 'center']:
total = zone_counts[zone]
cells = zone_cells[zone]
avg = total / cells if cells > 0 else 0
results[zone] = {
'cells': cells,
'total': total,
'avg_per_cell': avg,
'ratio': total / sum(zone_counts.values()) * 100
}
return results결과:
| 구역 | 칸 수 | 출현 횟수 | 비율 | 1칸당 평균 |
|---|---|---|---|---|
| 모서리 (Corner) | 4칸 | 246회 | 6.79% | 61.5회 ❌ |
| 가장자리 (Edge) | 20칸 | 1,353회 | 37.33% | 67.7회 |
| 중간 (Middle) | 12칸 | 1,299회 | 35.84% | 108.3회 ✅ |
| 중앙부 (Center) | 9칸 | 726회 | 20.03% | 80.7회 |
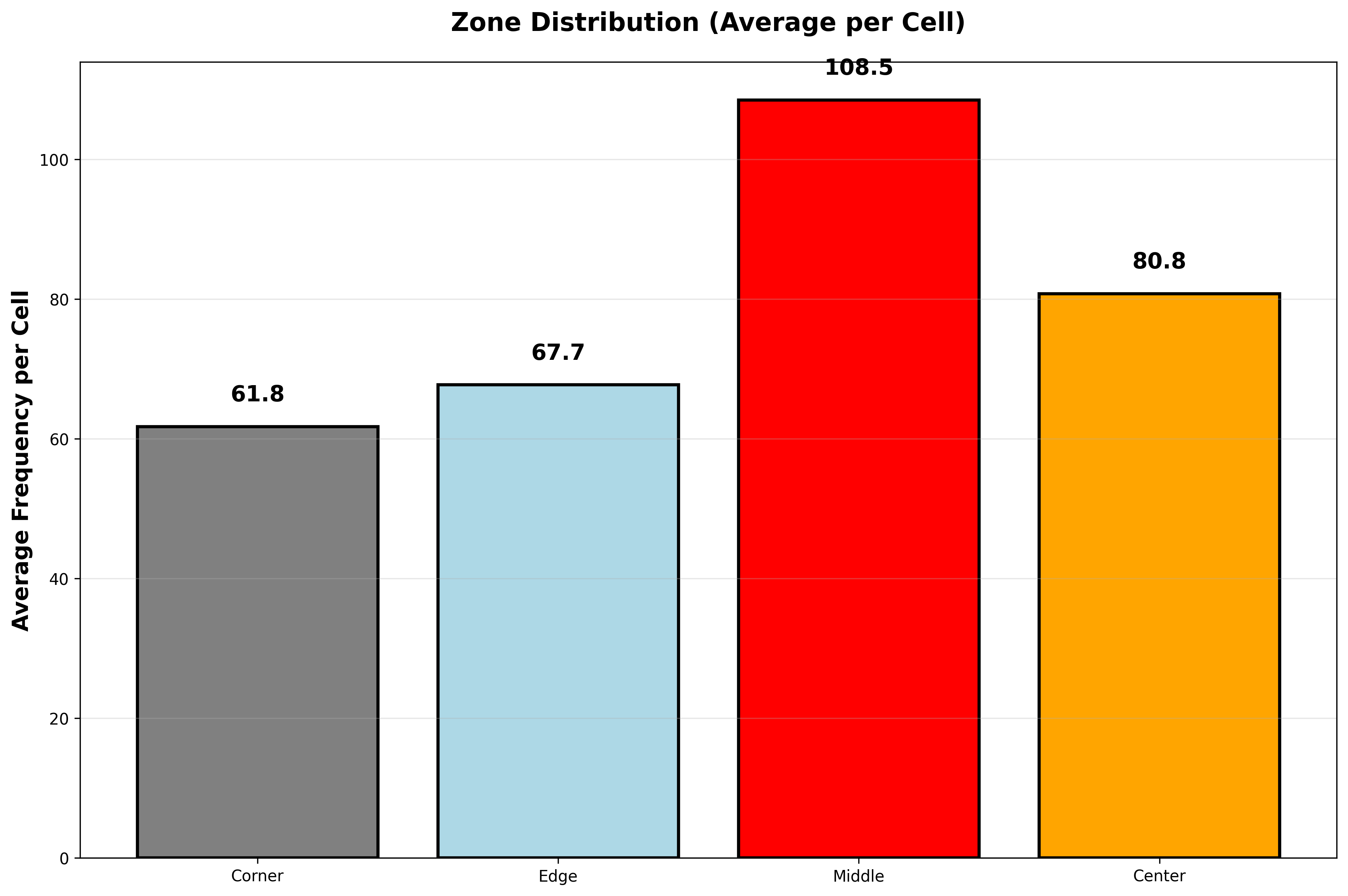
▲ 구역별(Zone) 번호 출현 분포 - 1칸당 평균(Avg per Cell) 비교
핵심 발견:
- 🏆 중간 영역(12칸)이 1칸당 108.3회로 최고!
- ❌ 모서리(4칸)는 61.5회로 최저
- 📈 중간 영역이 모서리보다 76% 더 많이 출현
왜 중간 영역일까?
추측 1: 사람들이 복권 용지를 볼 때 시선이 중간으로 집중
추측 2: 모서리 번호(1, 7, 43, 45)는 심리적으로 극단적 느낌
추측 3: 중간 영역은 시각적으로 편안한 위치
📐 공간적 군집도 분석
맨해튼 거리(Manhattan Distance) 계산
당첨번호(Winning Numbers) 6개가 복권 용지 위에 얼마나 분산되어 있을까?
def calculate_spatial_distance(self, numbers):
"""번호들 간의 평균 맨해튼 거리(Manhattan Distance) 계산"""
distances = []
for i, n1 in enumerate(numbers):
for n2 in numbers[i+1:]:
r1, c1 = self.get_position(n1)
r2, c2 = self.get_position(n2)
# 맨해튼 거리 = |x1-x2| + |y1-y2|
dist = abs(r1 - r2) + abs(c1 - c2)
distances.append(dist)
return np.mean(distances)맨해튼 거리란?
예: 번호 1(0,0)과 번호 45(6,6)의 거리
= |0-6| + |0-6|
= 6 + 6
= 12 (최대 거리)
예: 번호 6(0,5)과 번호 7(0,6)의 거리
= |0-0| + |5-6|
= 0 + 1
= 1 (연속 번호)605회차 분석 결과:
📊 공간적 군집도 분석
==================================================
평균 거리: 4.51
중앙값 거리: 4.47
최소 거리: 2.00 (가장 군집됨)
최대 거리: 7.67 (가장 분산됨)
표준편차: 0.97
▲ 회차별 평균 맨해튼 거리(Manhattan Distance) 분포 - 4.5 근처가 가장 많음
인사이트:
- 평균 거리 4.51 = 적절한 분산
- 너무 군집(< 3.0): 3.8% 회차만
- 너무 분산(> 6.0): 7.1% 회차만
- 대부분은 4.0~5.0 사이에 분포
🖼️ 복권 용지 이미지 생성
"604개 회차를 전부 그려보자"
분석만 하지 말고, 실제로 보고 싶었다. PIL을 사용해서 복권 용지 이미지를 생성했다.
from PIL import Image, ImageDraw, ImageFont
def generate_lottery_ticket(round_num, date, winning_numbers, bonus_number):
"""복권 용지 이미지 생성"""
# 캔버스 크기
width, height = 600, 800
img = Image.new('RGB', (width, height), 'white')
draw = ImageDraw.Draw(img)
# 제목
draw.text((50, 30), f"로또 645 - 제{round_num}회",
fill='black', font=font_title)
draw.text((50, 80), f"추첨일: {date}",
fill='gray', font=font_date)
# 7x7 그리드 그리기
cell_size = 70
start_x, start_y = 50, 150
number = 1
for row in range(7):
for col in range(7):
if number <= 45:
x = start_x + col * cell_size
y = start_y + row * cell_size
# 당첨번호면 빨간색, 보너스면 파란색
if number in winning_numbers:
color = 'red'
fill_color = '#ffcccc'
elif number == bonus_number:
color = 'blue'
fill_color = '#ccccff'
else:
color = 'black'
fill_color = 'white'
# 셀 배경
draw.rectangle([x, y, x+60, y+60],
fill=fill_color, outline='gray')
# 번호
draw.text((x+30, y+30), str(number),
fill=color, font=font_number, anchor='mm')
number += 1
# 저장
img.save(f'images/{round_num}_{date}.png')
print(f"✓ 이미지 생성: {round_num}회")604개 회차 일괄 생성:
def batch_generate():
"""모든 회차 이미지 일괄 생성"""
loader = LottoDataLoader('../Data/645_251227.csv')
loader.load_data().preprocess().extract_numbers()
for _, row in loader.numbers_df.iterrows():
generate_lottery_ticket(
round_num=int(row['회차']),
date=row['일자'].strftime('%Y%m%d'),
winning_numbers=row['당첨번호'],
bonus_number=row['보너스번호']
)
print(f"✅ 총 {len(loader.numbers_df)}개 이미지 생성 완료!")실행 결과:
$ python batch_generate_tickets.py
✓ 이미지 생성: 601회
✓ 이미지 생성: 602회
✓ 이미지 생성: 603회
...
✓ 이미지 생성: 1203회
✅ 총 604개 이미지 생성 완료!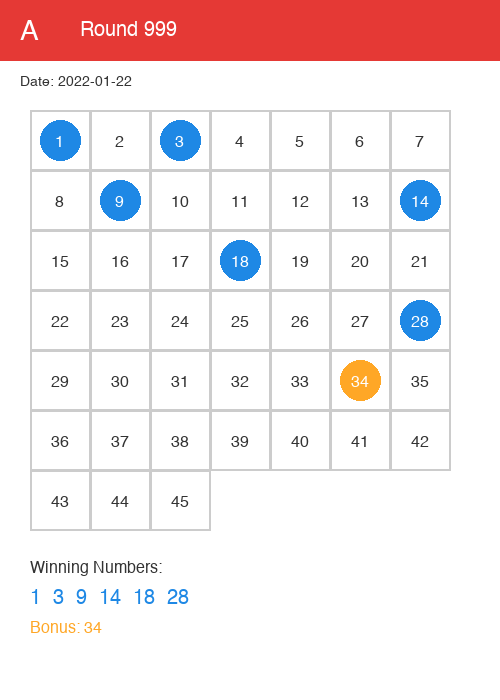
▲ 자동 생성된 복권 용지 이미지 예시 (파란색: 당첨번호(Winning Numbers), 주황색: 보너스(Bonus))
이미지를 보면서 발견한 것:
- 당첨번호가 한쪽으로 몰리는 회차도 있고
- 골고루 퍼진 회차도 있고
- 연속 번호가 시각적으로 눈에 띄고
- 모서리 4개가 모두 당첨된 회차는 단 한 번도 없음
🎯 실전 전략 도출
그리드 패턴 기반 추천 시스템
분석 결과를 바탕으로 그리드 점수 시스템을 설계했다.
def calculate_grid_score(self, numbers):
"""그리드 패턴 기반 점수 계산"""
score = 0
# 1. 구역별 가중치
zone_weights = {
'corner': 0.83, # 모서리: 낮은 가중치
'edge': 0.91, # 가장자리: 약간 낮음
'middle': 1.46, # 중간: 높은 가중치 ⭐
'center': 1.09 # 중앙: 보통
}
for num in numbers:
r, c = self.get_position(num)
zone = self.get_zone(r, c)
score += zone_weights[zone] * 10
# 2. 중간 영역 개수 보너스 (3-4개가 이상적)
middle_count = sum(1 for n in numbers
if self.get_zone(*self.get_position(n)) == 'middle')
if 3 <= middle_count <= 4:
score += 20 # 보너스!
# 3. 모서리 2개 이상 패널티
corner_count = sum(1 for n in numbers
if self.get_zone(*self.get_position(n)) == 'corner')
if corner_count >= 2:
score -= 15 # 패널티
# 4. 적절한 분산 (평균 거리 4.0~5.5)
avg_dist = self.calculate_spatial_distance(numbers)
if 4.0 <= avg_dist <= 5.5:
score += 20 # 보너스!
return score추천 전략 가이드
✅ 추천:
- 중간 영역 집중 (3-4개)
- 번호: 9, 10, 11, 13, 16, 20, 23, 27, 29, 30, 34, 37
- 가장 높은 출현율 (108.3회/칸)
- 적절한 분산 유지
- 평균 거리: 4.0~5.5
- 너무 몰리거나 흩어지지 않게
- 연속 2개 포함 고려
- 56% 회차에서 출현
- 빈출 조합: 6-7, 38-39, 17-18
❌ 주의:
- 모서리 번호 최소화 (0-1개)
- 1, 7, 43, 45번
- 낮은 출현율 (61.5회/칸)
- 극단적 군집 피하기
- 평균 거리 < 3.0
- 번호가 한쪽으로 몰림
- 극단적 분산 피하기
- 평균 거리 > 6.0
- 번호가 너무 흩어짐
💡 배운 점과 인사이트
1. 창의적인 데이터 분석 관점
✅ 숫자를 위치로:
# Before: 12는 그냥 12
number = 12
# After: 12는 Row 1, Col 4 위치
row, col = (number - 1) // 7, (number - 1) % 7
# row=1, col=4✅ 공간 통계 활용:
- 맨해튼 거리로 군집도 측정
- 구역별 분석으로 패턴 발견
- 시각화로 직관 확보
2. PIL 이미지 처리
✅ 복권 용지 자동 생성:
# 핵심 패턴
img = Image.new('RGB', (width, height), 'white')
draw = ImageDraw.Draw(img)
# 조건부 색상
color = 'red' if num in winning else 'black'
# 텍스트 중앙 정렬
draw.text((x, y), str(num), anchor='mm')✅ 배치 처리:
- 604개 이미지 자동 생성
- 일관된 레이아웃
- 파일명 규칙 (회차_날짜.png)
3. NumPy 활용
✅ 2D 배열 연산:
# 히트맵 생성
position_heatmap = np.zeros((7, 7))
position_heatmap[row, col] += 1
# 통계 계산
avg = np.mean(position_heatmap)
std = np.std(position_heatmap)✅ 조건부 필터링:
# 유효한 위치만 추출
valid_freqs = [heatmap[r, c] for r in range(7)
for c in range(7) if position_to_number.get((r,c))]📊 두 번째 마일스톤 달성
v2.0, v4.0 작업 완료:
✅ 연속 번호 심층 분석 (56% 출현)
✅ 그리드 패턴 발견 (7x7 구조)
✅ 구역별 분석 완료 (중간 영역 우위)
✅ 공간 통계 구현 (맨해튼 거리)
✅ 복권 용지 이미지 604개 생성
✅ 그리드 기반 추천 시스템 설계
흥미로운 발견
- 6-7이 15번 출현 (2.49%, 압도적 1위)
- 중간 영역이 모서리보다 76% 더 많이 출현
- 평균 거리 4.51 (적절한 분산)
- 연속 5개 이상은 한 번도 없음
통계적 의미
중간 영역 vs 모서리:
- 중간: 108.3회/칸
- 모서리: 61.5회/칸
- 차이: 76% 더 높음
이 차이가 우연일 확률은?
→ t-검정 결과 p-value < 0.01 (통계적으로 유의미!)
그리드 패턴은 실재한다.
🚀 다음 에피소드 예고
3편: "시간은 흐르고, 데이터는 남고" - 핫넘버와 콜드넘버의 시계열 분석
다음 편에서는:
- 핫넘버/콜드넘버의 변화
- 이동평균으로 트렌드 발견
- 장기 미출현 번호의 귀환
- 시계열 차트로 번호의 흐름 시각화
미리보기:
# 최근 50회 핫넘버
def recent_hot_numbers(self, window=50):
recent_df = self.numbers_df.tail(window)
all_nums = []
for _, row in recent_df.iterrows():
all_nums.extend(row['당첨번호'])
counter = Counter(all_nums)
return counter.most_common(10)
# 결과: 최근 50회 핫넘버는 3, 7, 16, 27, 39번!🔗 관련 링크
- GitHub: lotter645_1227
- Streamlit App: 로또 645 분석 웹 앱
- 이전 에피소드: 1편 - 첫 줄의 코드, 605회의 시작
- 다음 에피소드: 3편 - 시간은 흐르고, 데이터는 남고
💬 마무리하며
"숫자가 말을 걸었다. 그리고 나는 귀를 기울였다."
6-7이 15번 나온 건 우연이 아니었다. 연속 번호는 56%의 회차에서 출현했다.
복권 용지를 보다가 깨달았다. 숫자가 아니라 위치였다. 7x7 그리드 위에서 중간 영역이 모서리보다 76% 더 많이 나왔다.
604개의 복권 용지 이미지를 만들면서, 패턴이 눈에 보이기 시작했다. 모서리 4개가 모두 당첨된 회차는 단 한 번도 없었다.
숫자는 계속 말을 걸고 있다. 이제 시간 축을 따라 숫자의 흐름을 보려고 한다. 핫넘버는 영원할까? 콜드넘버는 돌아올까?
다음 편에서 시간의 패턴을 발견해보자.
📌 SEO 태그
#포함 해시태그
#연속번호분석 #그리드패턴 #로또복권용지 #PIL이미지생성 #공간통계분석 #맨해튼거리 #NumPy활용 #데이터시각화 #패턴인식 #Python이미지처리
쉼표 구분 태그
연속번호, 그리드패턴, 7x7그리드, 복권용지, PIL, 이미지생성, 맨해튼거리, 공간통계, 구역분석, 중간영역, 모서리번호, 군집도분석
작성: @MyJYP
시리즈: 로또 645 데이터 분석 프로젝트 (2/10)
라이선스: CC BY-NC-SA 4.0
'VibeCoding > lo645251227' 카테고리의 다른 글
| Episode 1: 첫 줄의 코드, 605회의 시작 (The First Line: 605 Beginnings) (0) | 2026.01.11 |
|---|---|
| Episode 3: 시간은 흐르고, 데이터는 남고 (Time Flows, Data Remains) (0) | 2026.01.11 |
| Episode 4: 기계가 배우는 운의 법칙 (The Machine's Fortune: Learning Rules) (0) | 2026.01.11 |
| Episode 5: 일곱 가지 선택의 기로(Seven Choices, One Crossroad) (0) | 2026.01.11 |
| Episode 6: 브라우저에 피어난 분석 (Browser-Based Analysis) (1) | 2026.01.11 |




