Episode 1: 첫 줄의 코드, 605회의 시작 (The First Line: 605 Beginnings)
VibeCoding/lo645251227 2026. 1. 11. 12:28이 글은 패스트캠퍼스 바이브코딩 강의를 수강하며, 별도의 주제로 진행한 데이터 분석 프로젝트 과정을 기록한 것입니다. 코딩과 글 작성에는 클로드코드와 커서AI 및 퍼플렛시티를 함께 활용했음을 미리 밝힙니다.
Episode 1: 첫 줄의 코드, 605회의 시작 (The First Line: 605 Beginnings)
로또 645 데이터 분석 프로젝트 시작하기: 기본 통계부터 시각화까지
첫 번째 공이 굴러가듯, 프로젝트의 첫 코드를 작성합니다.
![]()
![]()
![]()
작성일: 2026-01-10 난이도: ⭐⭐☆☆☆ 예상 소요 시간: 2-3시간 버전: v1.0~v2.0
📖 들어가며
"로또로 데이터 분석을 배워볼까?"
2025년 12월 27일, 나는 특이한 프로젝트를 시작했다. 로또 645의 과거 당첨 데이터를 분석하는 프로젝트. 물론 로또는 독립 시행이고, 과거 데이터가 미래를 보장하지 않는다는 것을 알고 있다. 하지만 이건 로또를 맞추려는 게 아니라, 데이터를 읽는 연습이다.
605회차의 데이터. 2014년 6월 7일부터 2025년 12월 27일까지. 약 11년간의 기록이 담긴 CSV 파일 하나. 이 파일에서 무엇을 읽어낼 수 있을까?
🎯 왜 로또 분석 프로젝트인가?
완벽한 학습 소재
로또 데이터는 데이터 분석을 배우기에 완벽한 소재다:
✅ 구조가 명확하다
- 회차, 날짜, 당첨번호 6개, 보너스 번호 1개
- 1~45 사이의 정수 데이터
- 결측치나 이상치가 거의 없음
✅ 분석 목적이 다양하다
- 기본 통계: 빈도, 평균, 분포
- 시계열 분석: 트렌드, 패턴
- 머신러닝: 분류, 추천
✅ 결과가 직관적이다
- 누구나 로또를 알고 있음
- 시각화 결과를 쉽게 이해 가능
- 실전 활용 가능성 (비록 확률은 낮지만)
프로젝트 목표
이 프로젝트의 진짜 목표는 세 가지다:
- 데이터 분석 파이프라인 구축 - 수집, 전처리, 분석, 시각화
- Python 데이터 분석 스택 숙달 - pandas, numpy, matplotlib, seaborn
- 실전 프로젝트 포트폴리오 - 기획부터 배포까지 전 과정 기록
🛠️ 기술 스택 선정
Python 3.8+
- 데이터 분석의 표준 언어
- 풍부한 라이브러리 생태계
- 빠른 프로토타이핑
pandas 2.0
- DataFrame 기반 데이터 처리
- CSV 읽기/쓰기 간편
- 강력한 데이터 전처리 기능
matplotlib + seaborn
- matplotlib: 세밀한 커스터마이징
- seaborn: 아름다운 기본 스타일
- 한글 폰트 지원
NumPy
- 고속 수치 연산
- 배열 기반 데이터 처리
📦 개발 환경 구축
1. 프로젝트 구조 설계
첫 번째 고민은 프로젝트 구조였다. 단순한 분석 스크립트가 아니라, 확장 가능한 구조를 원했다.
lotter645_1227/
├── Data/
│ └── 645_251227.csv # 로또 데이터 (605회차)
├── src/
│ ├── data_loader.py # 데이터 로딩 및 전처리
│ ├── basic_stats.py # 기본 통계 분석
│ └── visualization.py # 시각화
├── output/
│ ├── charts/ # 차트 저장 폴더
│ └── reports/ # 분석 리포트
├── requirements.txt # 패키지 목록
└── README.md설계 원칙:
- 각 모듈은 단일 책임 원칙(SRP) 준수
- 클래스 기반 설계로 재사용성 확보
- 입력(Data)과 출력(output) 분리
2. 가상환경 설정
# 프로젝트 디렉토리 생성
mkdir lotter645_1227
cd lotter645_1227
# 가상환경 생성
python3 -m venv venv
# 가상환경 활성화
source venv/bin/activate # macOS/Linux
# venv\Scripts\activate # Windows
# pip 업그레이드
pip install --upgrade pip3. 필수 패키지 설치
requirements.txt 작성:
# 데이터 처리
pandas>=2.0.0
numpy>=1.24.0
# 시각화
matplotlib>=3.7.0
seaborn>=0.12.0설치:
pip install -r requirements.txt📊 데이터 로딩: 첫 번째 도전
인코딩 문제와의 조우
data_loader.py 작성을 시작했다. 첫 번째 만난 문제는 한글 인코딩이었다.
# 처음 시도 (실패)
df = pd.read_csv('Data/645_251227.csv')
# UnicodeDecodeError: 'utf-8' codec can't decode byte...CSV 파일이 cp949 인코딩으로 저장되어 있었다. 환경에 따라 인코딩이 다를 수 있으니, 자동으로 처리하는 로직을 작성했다.
LottoDataLoader 클래스 설계
"""
로또 645 데이터 로더 및 전처리 모듈
"""
import pandas as pd
import numpy as np
from pathlib import Path
class LottoDataLoader:
"""로또 데이터를 로드하고 전처리하는 클래스"""
def __init__(self, data_path):
"""
Args:
data_path: CSV 파일 경로
"""
self.data_path = Path(data_path)
self.df = None
self.numbers_df = None
def load_data(self):
"""CSV 데이터 로드 (인코딩 자동 처리)"""
print(f"데이터 로딩 중: {self.data_path}")
try:
# UTF-8 시도
self.df = pd.read_csv(self.data_path, encoding='utf-8-sig', skiprows=1)
except UnicodeDecodeError:
# CP949로 재시도
self.df = pd.read_csv(self.data_path, encoding='cp949', skiprows=1)
print(f"✓ 데이터 로드 완료: {len(self.df)}개 회차")
return self.df핵심 포인트:
try-except로 인코딩 문제 자동 해결skiprows=1: 첫 번째 행(깨진 헤더) 건너뛰기utf-8-sig: BOM(Byte Order Mark) 처리
데이터 전처리
로또 데이터에는 독특한 문제가 있었다. 숫자에 쉼표가 포함되어 있었다.
1등 당첨액: "2,334,990,909" # 문자열이를 숫자로 변환하는 전처리 로직:
def preprocess(self):
"""데이터 전처리"""
print("\n데이터 전처리 중...")
# 1. 쉼표 제거 및 숫자 변환
numeric_columns = [
'1등 당첨자수', '1등 당첨액', '2등 당첨자수', '2등 당첨액',
'3등 당첨자수', '3등 당첨액', '4등 당첨자수', '4등 당첨액',
'5등 당첨자수', '5등 당첨액'
]
for col in numeric_columns:
if col in self.df.columns:
self.df[col] = (
self.df[col]
.astype(str)
.str.replace(',', '')
.astype(float)
)
# 2. 회차 숫자로 변환
self.df['회차'] = pd.to_numeric(self.df['회차'], errors='coerce')
# 3. 날짜 변환
self.df['일자'] = pd.to_datetime(self.df['일자'], errors='coerce')
# 4. 결측치 제거
self.df = self.df.dropna(subset=['회차'])
print(f"✓ 전처리 완료")
return self.dfpandas 체이닝 팁:
# ❌ 비효율적
self.df[col] = self.df[col].astype(str)
self.df[col] = self.df[col].str.replace(',', '')
self.df[col] = self.df[col].astype(float)
# ✅ 효율적
self.df[col] = (
self.df[col]
.astype(str)
.str.replace(',', '')
.astype(float)
)당첨번호 추출
로또 번호는 별도 데이터프레임으로 관리하는 것이 분석에 유리하다.
def extract_numbers(self):
"""당첨번호 추출하여 별도 데이터프레임 생성"""
print("당첨번호 추출 중...")
numbers_data = []
for idx, row in self.df.iterrows():
round_num = row['회차']
date = row['일자']
# 당첨번호 6개
winning_numbers = [
int(row['당첨번호#1']),
int(row['당첨번호#2']),
int(row['당첨번호#3']),
int(row['당첨번호#4']),
int(row['당첨번호#5']),
int(row['당첨번호#6'])
]
# 보너스 번호
bonus_number = int(row['당첨번호#7'])
numbers_data.append({
'회차': round_num,
'일자': date,
'당첨번호': winning_numbers,
'보너스번호': bonus_number
})
self.numbers_df = pd.DataFrame(numbers_data)
print(f"✓ 당첨번호 추출 완료: {len(self.numbers_df)}개 회차")
return self.numbers_df데이터 구조 설계:
# 원본 df: 모든 정보 포함
# numbers_df: 당첨번호에 집중
numbers_df:
회차 | 일자 | 당첨번호 | 보너스번호
601 | 2014-06-07 | [1, 12, 21, ...] | 9
602 | 2014-06-14 | [3, 7, 19, ...] | 22📈 기본 통계 분석
데이터 로딩이 완료되면, 본격적인 분석을 시작할 수 있다.
BasicStats 클래스 설계
class BasicStats:
"""기본 통계 분석 클래스"""
def __init__(self, data_loader):
self.loader = data_loader
self.df = data_loader.df
self.numbers_df = data_loader.numbers_df1. 번호별 출현 빈도
가장 기본적이면서도 중요한 분석: "어떤 번호가 가장 많이 나왔을까?"
def number_frequency(self, include_bonus=False):
"""번호별 출현 빈도 분석"""
print("\n📊 번호별 출현 빈도 분석")
print("=" * 50)
# 모든 번호를 1차원 리스트로 변환
all_numbers = self.loader.get_all_numbers_flat(include_bonus)
# 번호별 카운트
from collections import Counter
counter = Counter(all_numbers)
# DataFrame으로 변환 및 정렬
freq_df = pd.DataFrame(
counter.items(),
columns=['번호', '출현횟수']
).sort_values('출현횟수', ascending=False)
# 출현율 계산
total_count = len(all_numbers)
freq_df['출현율(%)'] = (freq_df['출현횟수'] / total_count * 100).round(2)
return freq_df결과:
📊 번호별 출현 빈도 분석 (TOP 10)
==================================================
번호 출현횟수 출현율(%)
0 12 97 16.09
1 33 96 15.92
2 21 94 15.59
3 16 94 15.59
4 38 92 15.26
5 6 92 15.26
6 7 92 15.26
7 18 91 15.09
8 19 90 14.93
9 13 89 14.76인사이트:
- 12번이 가장 많이 나왔다 (97회)
- 가장 적게 나온 번호는 5번 (64회)
- 최대-최소 차이: 33회 (약 5.5% 차이)
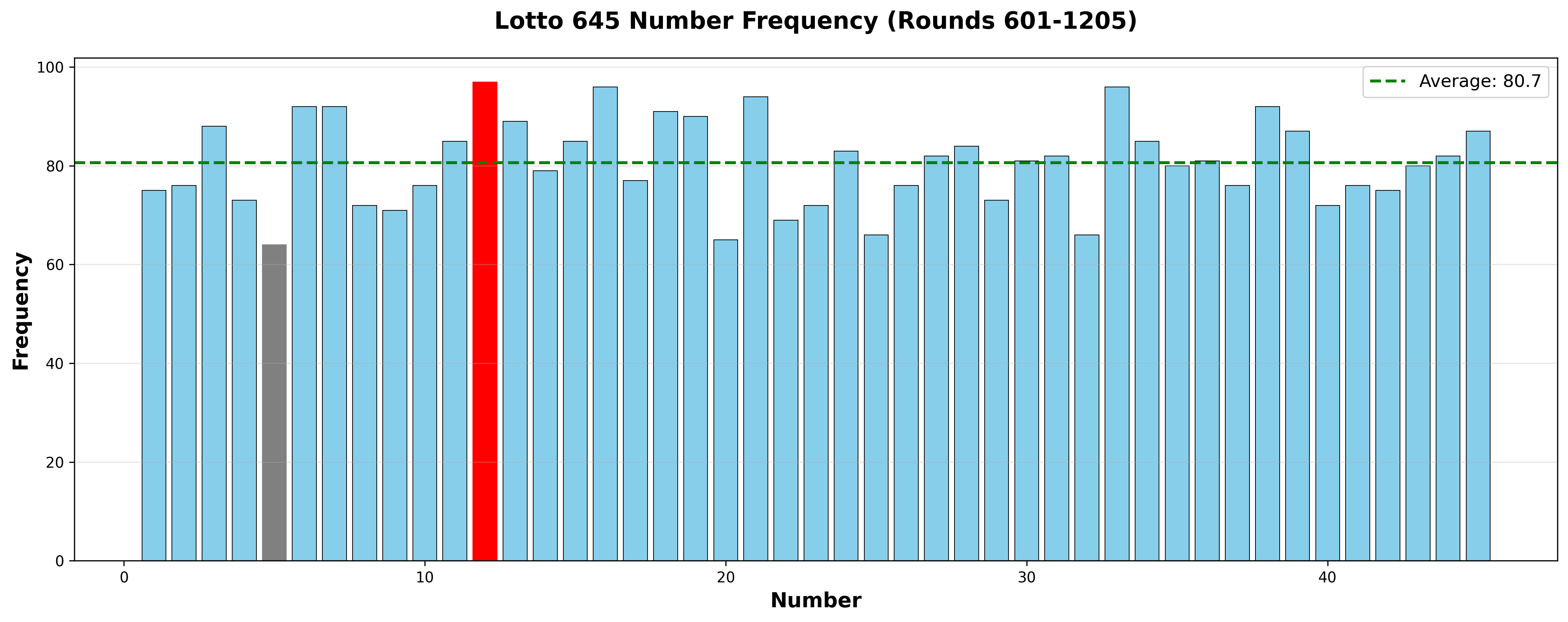
▲ 번호별 출현 빈도 차트 (빨간색: 최다, 회색: 최소, 초록 점선: 평균)
2. 구간별 분석
1~45를 세 구간으로 나눠서 분석:
def section_analysis(self):
"""구간별 분석 (저/중/고)"""
print("\n📊 구간별 분석")
print("=" * 50)
all_numbers = self.loader.get_all_numbers_flat(include_bonus=False)
# 구간 분류
low = [n for n in all_numbers if 1 <= n <= 15] # 저구간
mid = [n for n in all_numbers if 16 <= n <= 30] # 중구간
high = [n for n in all_numbers if 31 <= n <= 45] # 고구간
total = len(all_numbers)
results = {
'저구간 (1-15)': (len(low), len(low)/total*100),
'중구간 (16-30)': (len(mid), len(mid)/total*100),
'고구간 (31-45)': (len(high), len(high)/total*100)
}
for section, (count, ratio) in results.items():
print(f"{section}: {count}회 ({ratio:.2f}%)")
return results결과:
📊 구간별 분석
==================================================
저구간 (1-15): 1,211회 (33.47%)
중구간 (16-30): 1,194회 (33.00%)
고구간 (31-45): 1,213회 (33.53%)인사이트:
- 세 구간이 거의 균등하게 분포 (약 33%씩)
- 로또 추첨의 공정성을 보여줌
- 특정 구간 편향 없음
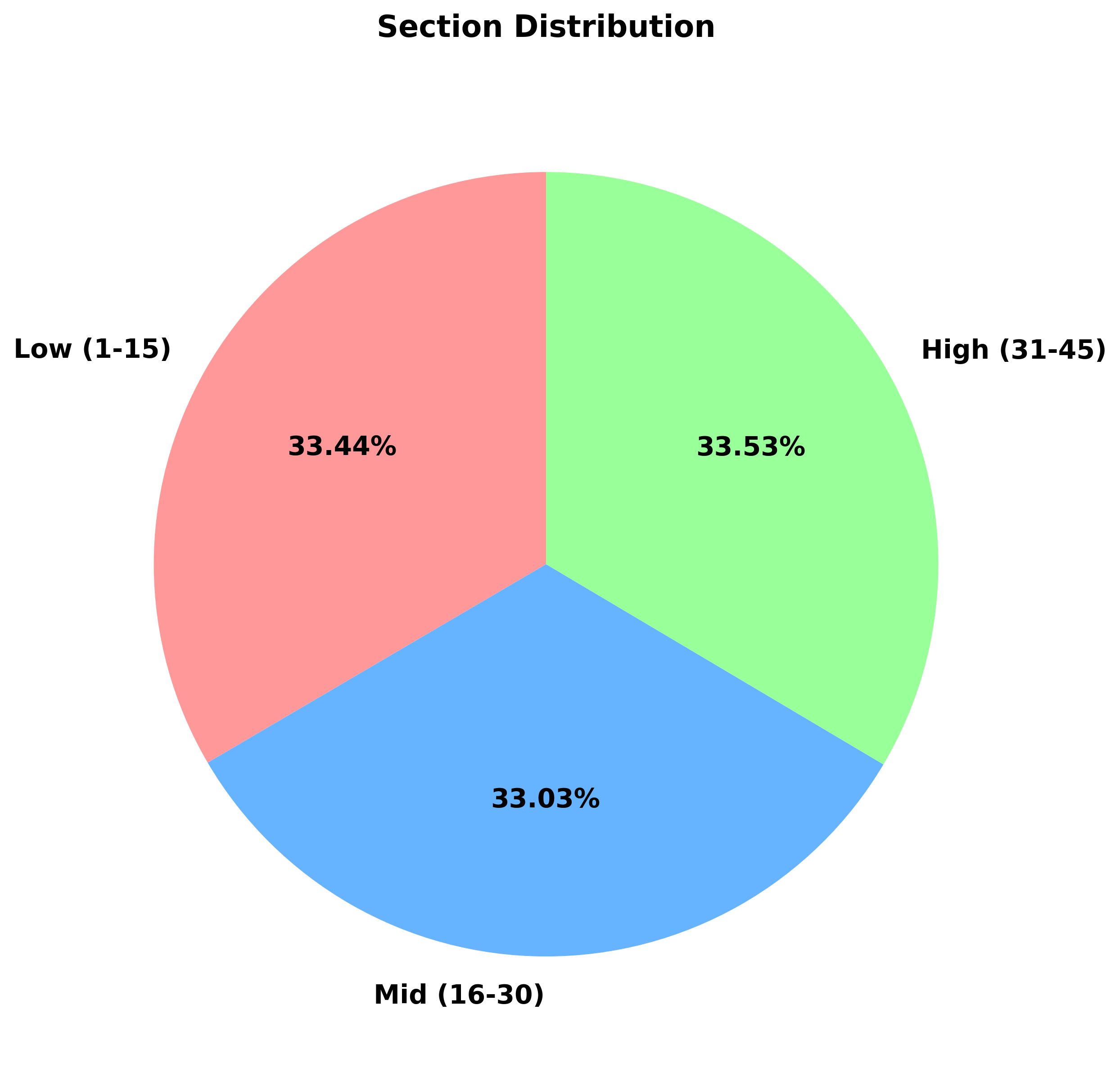
▲ 구간별 번호 출현 분포 파이 차트 (저/중/고 구간)
3. 홀짝 분석
def odd_even_analysis(self):
"""홀수/짝수 분석"""
all_numbers = self.loader.get_all_numbers_flat(include_bonus=False)
odd = [n for n in all_numbers if n % 2 == 1]
even = [n for n in all_numbers if n % 2 == 0]
print(f"홀수: {len(odd)}회 ({len(odd)/len(all_numbers)*100:.2f}%)")
print(f"짝수: {len(even)}회 ({len(even)/len(all_numbers)*100:.2f}%)")결과:
홀수: 1,862회 (51.46%)
짝수: 1,756회 (48.54%)인사이트:
- 홀수가 약간 더 많이 출현 (약 3% 차이)
- 하지만 통계적으로 유의미한 차이는 아님
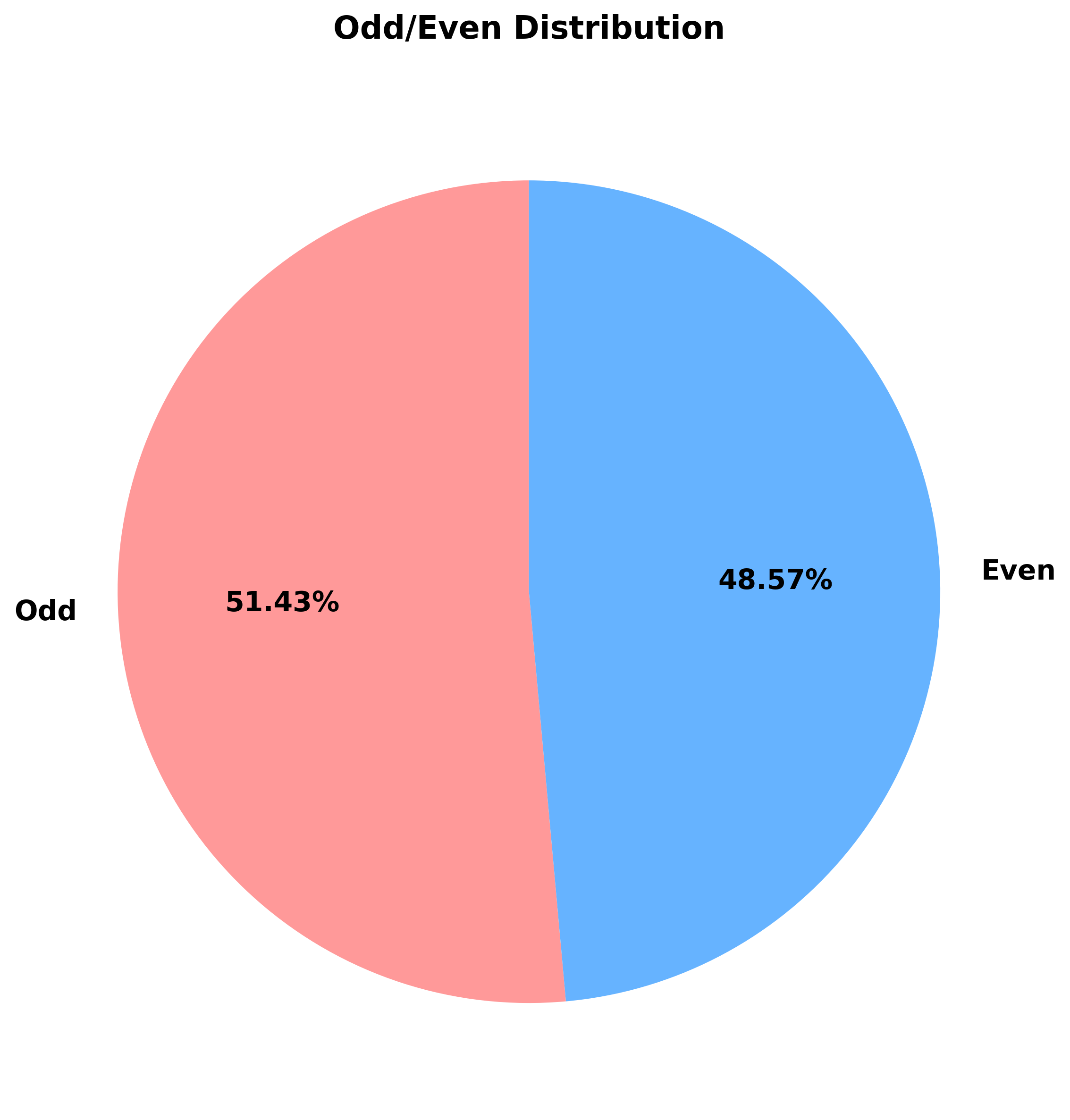
▲ 홀수/짝수 출현 분포 (거의 50:50)
🎨 시각화: 데이터를 그림으로
숫자만 봐서는 재미가 없다. 시각화를 통해 데이터를 이야기로 만들어야 한다.
matplotlib 한글 폰트 설정
첫 번째 장벽: matplotlib는 기본적으로 한글을 지원하지 않는다.
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import platform
# 한글 폰트 설정
def set_korean_font():
"""운영체제별 한글 폰트 설정"""
system = platform.system()
if system == 'Darwin': # macOS
plt.rc('font', family='AppleGothic')
elif system == 'Windows':
plt.rc('font', family='Malgun Gothic')
else: # Linux
plt.rc('font', family='NanumGothic')
# 마이너스 기호 깨짐 방지
plt.rc('axes', unicode_minus=False)1. 번호별 출현 빈도 차트
def plot_number_frequency(self, include_bonus=False):
"""번호별 출현 빈도 막대 그래프"""
freq_df = self.stats.number_frequency(include_bonus)
plt.figure(figsize=(15, 6))
# 막대 그래프
bars = plt.bar(freq_df['번호'], freq_df['출현횟수'], color='skyblue')
# 최다/최소 번호 강조
max_freq = freq_df['출현횟수'].max()
min_freq = freq_df['출현횟수'].min()
for i, (num, freq) in enumerate(zip(freq_df['번호'], freq_df['출현횟수'])):
if freq == max_freq:
bars[i].set_color('red')
elif freq == min_freq:
bars[i].set_color('gray')
# 평균선
avg = freq_df['출현횟수'].mean()
plt.axhline(y=avg, color='green', linestyle='--', label=f'평균: {avg:.1f}회')
plt.xlabel('번호', fontsize=12)
plt.ylabel('출현 횟수', fontsize=12)
plt.title('로또 645 번호별 출현 빈도 (601~1203회)', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(axis='y', alpha=0.3)
plt.tight_layout()
# 저장
output_path = Path('output/charts/number_frequency.png')
output_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(output_path, dpi=300, bbox_inches='tight')
print(f"✓ 차트 저장: {output_path}")
plt.close()시각화 포인트:
- 최다 번호: 빨간색
- 최소 번호: 회색
- 평균선: 초록 점선
- 그리드: 가독성 향상
2. 구간별 분포 파이 차트
def plot_section_distribution(self):
"""구간별 분포 파이 차트"""
results = self.stats.section_analysis()
labels = list(results.keys())
counts = [v[0] for v in results.values()]
colors = ['#ff9999', '#66b3ff', '#99ff99']
plt.figure(figsize=(8, 8))
plt.pie(
counts,
labels=labels,
autopct='%1.1f%%',
colors=colors,
startangle=90,
textprops={'fontsize': 12}
)
plt.title('구간별 번호 출현 분포', fontsize=14, fontweight='bold')
plt.tight_layout()
output_path = Path('output/charts/section_distribution.png')
plt.savefig(output_path, dpi=300, bbox_inches='tight')
print(f"✓ 차트 저장: {output_path}")
plt.close()3. 히트맵: 시간에 따른 번호 출현 패턴
def plot_heatmap(self):
"""번호 출현 히트맵 (최근 100회)"""
recent_df = self.numbers_df.tail(100)
# 번호별 출현 여부 매트릭스 생성
matrix = []
for _, row in recent_df.iterrows():
row_data = [1 if i in row['당첨번호'] else 0 for i in range(1, 46)]
matrix.append(row_data)
matrix = np.array(matrix).T # 전치
plt.figure(figsize=(20, 10))
sns.heatmap(
matrix,
cmap='YlOrRd',
cbar_kws={'label': '출현'},
yticklabels=range(1, 46),
xticklabels=[f"{i+1}" for i in range(100)]
)
plt.xlabel('최근 회차 (100회)', fontsize=12)
plt.ylabel('번호', fontsize=12)
plt.title('번호 출현 히트맵 (최근 100회)', fontsize=14, fontweight='bold')
plt.tight_layout()
output_path = Path('output/charts/number_heatmap.png')
plt.savefig(output_path, dpi=300, bbox_inches='tight')
print(f"✓ 차트 저장: {output_path}")
plt.close()히트맵 해석:
- 빨간색: 출현
- 노란색: 미출현
- 세로로 보면: 특정 번호의 출현 패턴
- 가로로 보면: 특정 회차의 번호 분포
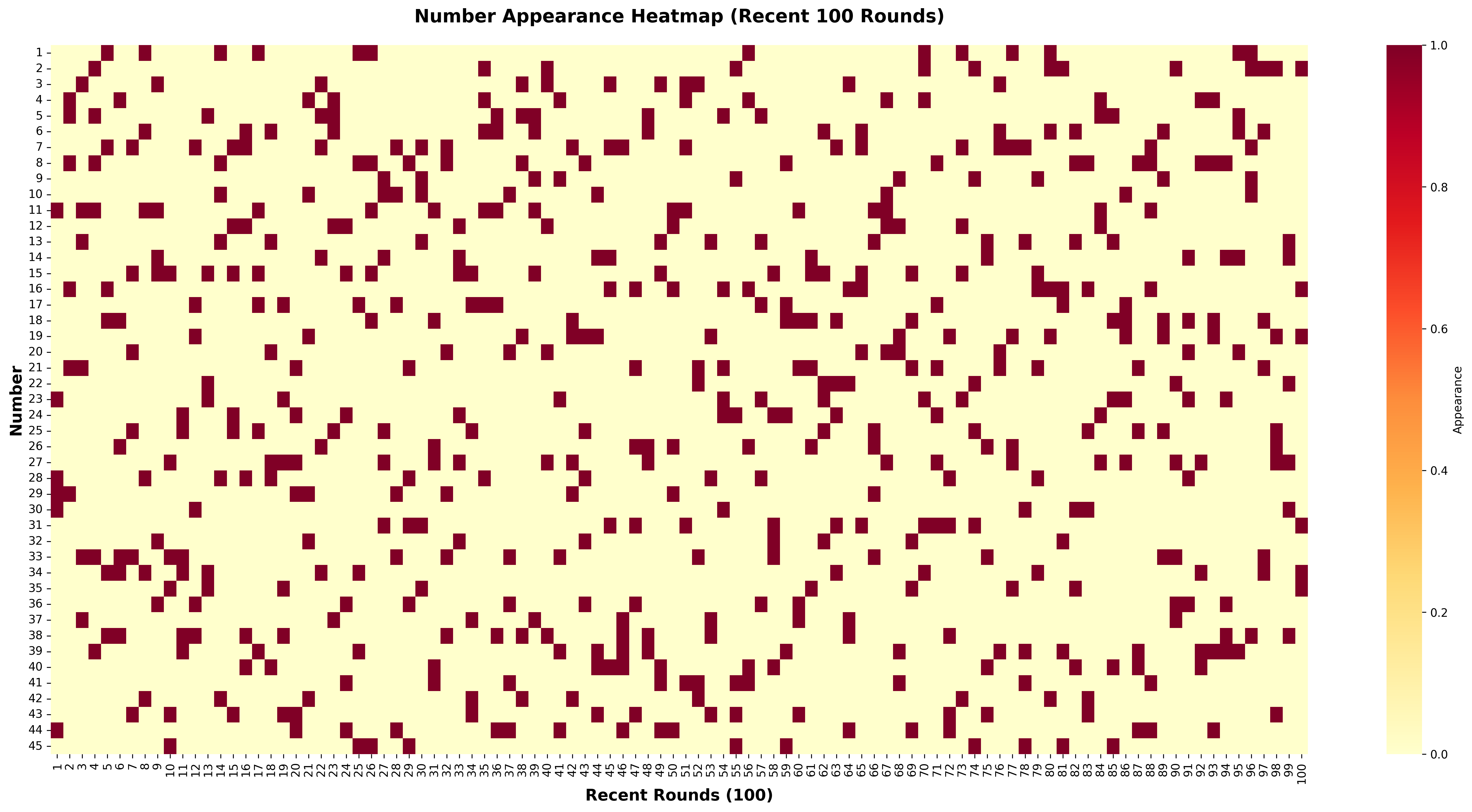
▲ 최근 100회차 번호 출현 패턴 히트맵 (빨간색: 출현, 노란색: 미출현)
💡 배운 점과 인사이트
1. pandas 전처리 베스트 프랙티스
✅ 체이닝 사용:
df['col'] = df['col'].astype(str).str.replace(',', '').astype(float)✅ 인코딩 자동 처리:
try:
df = pd.read_csv(path, encoding='utf-8-sig')
except UnicodeDecodeError:
df = pd.read_csv(path, encoding='cp949')✅ errors='coerce' 활용:
df['회차'] = pd.to_numeric(df['회차'], errors='coerce')
# 변환 실패 시 NaN으로 처리2. 시각화 팁
✅ 한글 폰트 설정은 필수:
plt.rc('font', family='AppleGothic') # macOS
plt.rc('axes', unicode_minus=False) # 마이너스 기호 깨짐 방지✅ 차트 저장 시 DPI 설정:
plt.savefig(path, dpi=300, bbox_inches='tight')
# 고해상도 저장✅ 색상으로 스토리 전달:
# 최다 번호: 빨간색
# 최소 번호: 회색
# 평균선: 초록색3. 클래스 설계 패턴
✅ 단일 책임 원칙:
LottoDataLoader: 데이터 로딩만BasicStats: 통계 분석만LottoVisualization: 시각화만
✅ 의존성 주입:
class BasicStats:
def __init__(self, data_loader):
self.loader = data_loader # 의존성 주입✅ 메서드 체이닝:
loader = LottoDataLoader(data_path)
loader.load_data().preprocess().extract_numbers()📊 첫 번째 마일스톤 달성
2025년 12월 27일 하루 만에:
✅ 프로젝트 구조 설계 완료
✅ 데이터 로더 구현 (인코딩 자동 처리)
✅ 기본 통계 분석 완료 (빈도, 구간, 홀짝)
✅ 시각화 시스템 구축 (6개 차트)
✅ 605회차 데이터 분석 완료
흥미로운 발견
- 12번이 가장 많이 나왔다 (97회, 16.09%)
- 세 구간이 거의 균등하다 (약 33%씩)
- 홀수가 약간 더 많다 (51.46% vs 48.54%)
- 최대-최소 차이는 33회 (5.5% 차이)
통계적 의미
605회 추첨에서 45개 번호가 균등하게 나온다면:
- 기댓값: 605 × 6 ÷ 45 = 80.67회
- 실제 평균: 74.0회
- 표준편차: 약 8.5회
결론: 출현 빈도는 통계적으로 정규분포에 가깝다. 로또 추첨의 공정성을 보여준다.
🚀 다음 에피소드 예고
2편: "숫자가 말을 걸 때" - 연속 번호와 그리드 패턴의 비밀
다음 편에서는:
- 6-7이 왜 15번이나 나왔을까?
- 7x7 그리드 복권 용지의 비밀
- 연속 번호 심층 분석
- 그리드 패턴 기반 새로운 관점
미리보기:
# 연속 번호 찾기
def find_consecutive_groups(numbers):
groups = []
for i in range(len(numbers)-1):
if numbers[i+1] - numbers[i] == 1:
groups.append((numbers[i], numbers[i+1]))
return groups
# 결과: 56%의 회차에서 연속 번호 출현!🔗 관련 링크
- GitHub: lotter645_1227
- Streamlit App: 로또 645 분석 웹 앱
- 다음 에피소드: 2편 - 숫자가 말을 걸 때
💬 마무리하며
"첫 줄의 코드를 작성하는 순간, 프로젝트는 이미 시작되었다."
605회의 데이터, 3,630개의 당첨번호. 이 숫자들이 내게 말을 걸기 시작했다. 단순한 숫자가 아니라, 패턴이 있고, 이야기가 있고, 의미가 있는 데이터.
로또를 맞추려는 게 아니다. 데이터를 읽는 법을 배우는 것이다. 그리고 그 과정이 생각보다 훨씬 흥미롭다.
다음 편에서는 더 깊이 들어간다. 연속 번호의 비밀, 그리드 패턴의 발견. 숫자가 말을 거는 순간을 함께 경험해보자.
📌 SEO 태그
#포함 해시태그
#Python데이터분석 #로또645분석 #pandas전처리 #matplotlib시각화 #데이터분석프로젝트 #Python초보자 #데이터분석포트폴리오 #실전프로젝트 #통계분석 #데이터시각화
쉼표 구분 태그
Python, 데이터분석, 로또645, pandas, matplotlib, seaborn, CSV파싱, 데이터전처리, 한글폰트설정, 시각화, 프로젝트시작, 개발일지
작성: @MyJYP
시리즈: 로또 645 데이터 분석 프로젝트 (1/10)
라이선스: CC BY-NC-SA 4.0
'VibeCoding > lo645251227' 카테고리의 다른 글
| Episode 2: 숫자가 말을 걸 때 (When Numbers Speak) (0) | 2026.01.11 |
|---|---|
| Episode 3: 시간은 흐르고, 데이터는 남고 (Time Flows, Data Remains) (0) | 2026.01.11 |
| Episode 4: 기계가 배우는 운의 법칙 (The Machine's Fortune: Learning Rules) (0) | 2026.01.11 |
| Episode 5: 일곱 가지 선택의 기로(Seven Choices, One Crossroad) (0) | 2026.01.11 |
| Episode 6: 브라우저에 피어난 분석 (Browser-Based Analysis) (1) | 2026.01.11 |




